A Mentira da Produtividade: Por que as Ferramentas de IA Fazem Você se Sentir Rápido, mas o Tornam Lento
O paradoxo da produtividade da IA: benchmarks reais vs. reivindicações de marketing, por que os desenvolvedores se sentem 20% mais rápidos, mas são na...
✨TL;DR / Sumário Executivo
O paradoxo da produtividade da IA: benchmarks reais vs. reivindicações de marketing, por que os desenvolvedores se sentem 20% mais rápidos, mas são na...
💡 TL;DR (Too Long; Didn't Read)
Principais conclusões em 60 segundos:
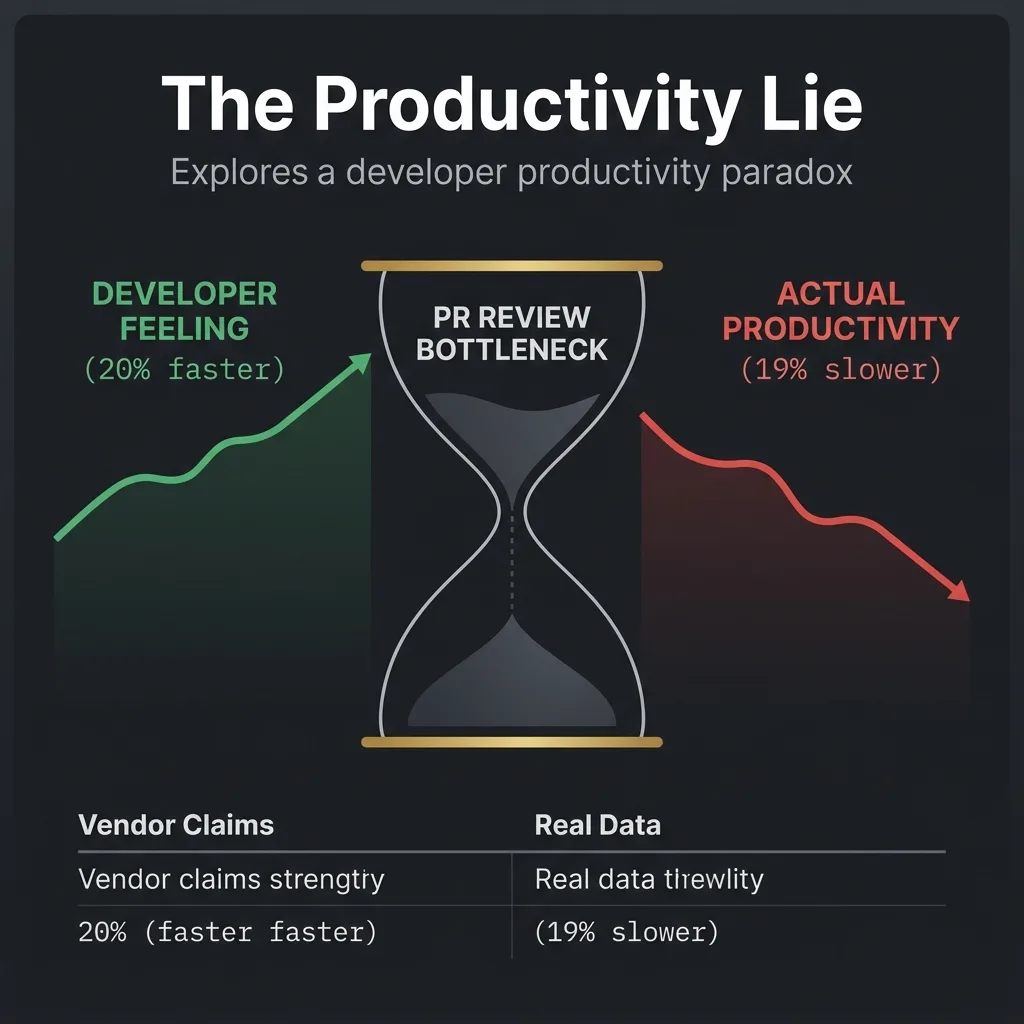
- O Paradoxo: Desenvolvedores relatam ganhos de produtividade de 20%+ com IA. Estudos controlados mostram que eles são, na verdade, 19% mais lentos, em média.
- Por quê: A revisão humana e a validação consomem o tempo que a IA economiza. Esse gargalo escala conforme o volume de código de IA aumenta.
- Números Reais: Economia média de tempo com ferramentas de IA: 3 horas e 45 minutos por semana, mas o aumento real de produtividade é de apenas 5–15% — não os 50–100% que os fornecedores prometem.
- A Solução: Pare de otimizar para "saída de código". Otimize para "largura de banda de revisão de código", pair-programming assíncrono e disciplina de medição.
- Armadilha do Benchmark: O SWE-bench mostra o Claude Opus 4.5 com 76,8% e os principais modelos agrupados perto de 80%, mas estes medem a precisão algorítmica, não a prontidão para produção.
O Paradoxo Visual
A Lacuna: Seu cérebro registra a saída da IA (2 segundos) e assume que esse é o seu ganho de produtividade. Não é. Sua produtividade real é a soma da intenção, geração, validação e iteração. A IA acelera apenas uma dessas quatro fases.
O Cenário: Por que Todos estão Mentindo para Você (Incluindo Eles Mesmos)
Você já ouviu os números. Você já viu as demos. O GitHub Copilot reduz o tempo de codificação pela metade. O Claude Code oferece "acelerações de desenvolvimento de 3x". O agente do Cursor "substitui um engenheiro júnior". A mensagem é consistente, as métricas são impressionantes e os canais do Slack da sua equipe estão cheios de desenvolvedores cantando louvores.
Então, por que seus gráficos de velocidade parecem os mesmos de 2024?
Verified SourceMETR (pesquisa de julho de 2025 e fevereiro de 2026)Em um ensaio controlado randomizado com 16 desenvolvedores experientes de código aberto (22k+ estrelas, 1M+ linhas de código), o uso de IA fez com que as tarefas levassem 19% mais tempo, em média. Os desenvolvedores estimaram que foram 20% mais rápidos. Ambos foram sinceros.
Este é o paradoxo da produtividade da IA, e não é uma conspiração — é matemática.
Parte 1: Por que seu Cérebro Mente para Você (E os Fornecedores também)
A Ilusão de Velocidade
Quando você usa o Claude Code ou o Cursor, a experiência é inegavelmente rápida:
- As sugestões aparecem com latência sub-segundo.
- Refatorações de múltiplos arquivos acontecem em minutos em vez de horas.
- O boilerplate se auto-sustenta.
Sua dopamina sobe. Você se sente produtivo. Mas você está medindo a coisa errada.
Aqui está o que realmente aconteceu:
- Você digitou um prompt (30 segundos).
- A IA gerou o código (2 segundos).
- Você leu a saída (2 minutos).
- Você encontrou problemas (5 minutos).
- Você os corrigiu manualmente (10 minutos).
- Você executou os testes; eles falharam (5 minutos).
- Você iterou com a IA (10 minutos).
- Você finalmente enviou (2 minutos).
Tempo total: 34,5 minutos. Se você tivesse escrito sem IA, poderia ter gasto 30 minutos pensando, depois 10 minutos digitando — 40 minutos no total. Você economizou talvez 5 minutos.
Mas você sente que levou 5 minutos porque a IA fez a parte da digitação.
Os Fornecedores Estão Medindo a Coisa Errada
Quando os fornecedores reivindicam "3x de aceleração", eles geralmente estão medindo linhas de código por minuto ou tempo até o primeiro commit. Nenhuma dessas métricas se correlaciona com o envio.
ReportedFaros AI (pesquisa de julho de 2025, 10.000 desenvolvedores)Desenvolvedores em equipes com alta adoção de IA completam 21% mais tarefas e mesclam 98% mais pull requests. Mas o tempo de revisão de PR aumenta 91%, e a taxa de falha de mudança aumenta 9%. Os bugs por desenvolvedor aumentam 9%, e o tamanho médio do PR aumenta 154%.
Tradução: A IA tornou mais fácil escrever código. A IA tornou mais difícil revisar, testar e enviar código. O gargalo simplesmente se moveu para o fluxo posterior (downstream).
Parte 2: Os Benchmarks Reais (E por que eles também Mentem)
O que o SWE-bench Realmente Mede
O ranking do SWE-bench mantém o Claude Opus 4.5 com 76,8%, com o Gemini 3.1 Pro, o Claude Sonnet 4.6 e o GLM-5 agrupados entre 77,8–80,9%. Essas são pontuações impressionantes. Mas sejamos honestos: o SWE-bench não mede a prontidão para produção.
O SWE-bench testa:
- O modelo consegue fechar issues do GitHub? ✅
- Ele gera código sintaticamente válido? ✅
- O código passa nos testes existentes? ✅
O SWE-bench NÃO testa:
- O código segue as convenções da equipe? ❌
- Um engenheiro júnior conseguirá entendê-lo em 6 meses? ❌
- Ele falhará em casos extremos que seus testes não cobrem? ❌
- Ele deixa brechas de segurança? ❌
Todos os três novos modelos (Gemini 3.1 Pro, Claude Sonnet 4.6, GLM-5) entram com ✅ total em todas as linhas de qualidade. Os benchmarks mostram as principais ferramentas atingindo 80% de geração de código em testes controlados, embora a validação humana permaneça indispensável para a prontidão de produção.
A meta-verdade honesta: Os benchmarks medem o que é fácil de medir, não o que importa.
A Ilusão da Adoção
Em 2026, 84% dos desenvolvedores usam ferramentas de IA, com 41% de todo o código gerado por IA em fluxos de trabalho reais. No entanto, as pesquisas mostram que a confiança nos resultados da IA varia de 29% a 46%, dependendo da senioridade da equipe e do tipo de tarefa — com uma média de cerca de 33%.
Reportedindex.dev Developer Productivity Survey (2026)Dados de adoção e confiança de uma pesquisa com desenvolvedores profissionais. A faixa de confiança de 29–46% reflete a variação entre níveis de senioridade e categorias de tarefas; 33% representa a média entre as coortes.
Deixe-me destacar essa lacuna: 41% do código é gerado por IA, mas apenas ~33% dos desenvolvedores confiam nele em média.
Essa lacuna de confiança é o tempo de revisão. Esse é o seu gargalo.
Parte 3: A Decomposição Honesta — Onde a IA Realmente Ajuda (E onde Não)
Vou cortar o marketing e apresentar as zonas reais onde a IA agrega valor:
✅ A IA Realmente Acelera
Scaffolding & Boilerplate
Escrever um novo endpoint de API, formulários CRUD ou infraestrutura como código? A IA brilha. Você economiza 15–25 minutos em uma configuração que era puramente mecânica. Essa é uma economia de tempo real porque a revisão é mínima.
Economia média de tempo com ferramentas de IA: 3 horas e 45 minutos por semana. Aumento real de produtividade: 5–15% — não os 50–100% que os fornecedores de ferramentas prometem.
Documentação & Testes
A IA pode gerar stubs de teste e boilerplate de README. Você corrige a lógica; a IA cuida do esqueleto. Economia real de tempo: 20–30%.
Refatoração de Padrões Conhecidos
"Converta este estado Redux para Zustand" ou "Divida este componente de 300 linhas em hooks personalizados". A IA lida com o padrão. Você valida a semântica. Economia: 30–40% real.
⚠️ A IA Cria Trabalho
Lógica de Negócio Complexa
A IA gerará código que parece correto, mas ignora requisitos implícitos. Um engenheiro Staff+ leva 5 minutos para escrevê-lo corretamente. A IA leva 3 minutos para gerá-lo incorretamente, então você gasta 20 minutos depurando. Custo líquido: +12 minutos.
Interações Multi-Serviço
Qualquer coisa envolvendo sistemas distribuídos, consistência eventual ou lógica sensível ao tempo? O contexto da IA é muito local. Ela gerará condições de corrida (race conditions) e impasses (deadlocks). É aqui que os engenheiros experientes ganham seu salário — e onde a IA agrega ROI negativo.
Código Crítico de Segurança
Autenticação, criptografia, controle de acesso, manipulação de segredos. Mesmo a coorte mais otimista atinge no máximo 46% de confiança nos resultados da IA — e a média entre as coortes é de apenas 33%. Para código de segurança, você deve ter 95%+ de confiança antes do envio. A IA não o leva até lá mais rápido — ela o leva mais devagar porque a revisão é mais intensa.
Parte 4: Fluxos de Trabalho que Realmente Funcionam
Se a IA realmente adiciona 5–15% de produtividade, você precisa arquitetar sua equipe para capturar esse valor. Aqui está o que funciona:
O Modelo de Pair-Programming Assíncrono
Em vez de a IA co-pilotar em tempo real (o que cria interrupção de fluxo), use-a de forma assíncrona:
- Fase de Spec (humano sozinho): Desenhe a mudança em prosa. Escreva os critérios de aceitação.
- Fase de Geração (IA sozinha): Gere em lote os scaffolds para todos os arquivos afetados. Faça o commit do WIP com uma mensagem clara.
- Fase de Revisão (humano sozinho): Revise todas as mudanças como uma unidade coesa. Você consegue ver o padrão e detectar inconsistências.
- Fase de Refinamento (IA sozinha): Com base no feedback, regenere as seções específicas.
Por que isso funciona: Humanos são bons em intenção. A IA é boa em reconhecimento de padrões. Separar essas fases permite que cada um faça o que faz melhor.
Disciplina de Medição
Pare de medir "linhas de código por sprint". Comece a medir:
- Taxa de Falha de Mudança (métrica DORA): Qual % do código enviado causa incidentes?
- Tempo de Revisão de PR: Quanto tempo desde a abertura do PR até a aprovação da mesclagem?
- Rotatividade de Código (Churn): Qual % do código é rescrito em até 30 dias após o envio?
- Delta de Cobertura de Teste: O código tocado pela IA tem cobertura de teste melhor, igual ou pior?
As quatro métricas DORA (frequência de implantação, lead time, taxa de falha de mudança, MTTR) são as únicas métricas que realmente se correlacionam com o desempenho de entrega de software em estudos de mais de 10.000 equipes.
Se a IA realmente melhorar a produtividade, essas métricas se moverão. Se não? Você terá visibilidade do porquê, e não apenas "a ferramenta não funciona".
Camadas de Ferramentas (Não Substituição)
As melhores equipes não estão usando uma ferramenta de IA. Elas estão sobrepondo:
- Assistente em tempo real no editor (Copilot, Claude Code no VS Code): Captura erros de digitação, completa boilerplate.
- Agente de terminal (Aider, Claude Code no terminal): Refatorações complexas de múltiplos arquivos, branches de features.
- Automação de revisão de código (Trunk Review, Revert-Check): Sinaliza automaticamente padrões suspeitos.
- Integração de CI (linting impulsionado por IA): Detecta problemas de estilo antes da revisão humana.
Cada camada lida com uma carga cognitiva diferente. Seu cérebro permanece focado na intenção. As ferramentas lidam com a mecânica.
Parte 5: O Reality Check para Staff+
Aqui é onde isso mais importa: você.
Se você é um Engenheiro Staff+ ou CTO, ferramentas de IA não multiplicam sua saída. Elas multiplicam sua alavancagem. Você gasta 30 minutos arquitetando uma funcionalidade. A IA gasta 3 minutos fazendo o scaffolding. Você gasta 30 minutos revisando a saída da IA para verificar correção e ajuste. Você envia uma funcionalidade que levaria 3 dias para sua equipe em 8 horas no total.
Isso não é uma aceleração de 3x. É você sendo 3x mais eficiente, o que é diferente. Você ainda é o gargalo. Você é apenas um gargalo melhor.
ReportedDeveloper Tools News (março de 2026)Em 2026, mais da metade dos desenvolvedores pesquisados incorporam agentes em seus fluxos de trabalho, com engenheiros seniores liderando a adoção com 63,5%. Ferramentas como os recursos de agente do Cursor e plataformas especializadas permitem a automação de tarefas de ponta a ponta.
A curva de adoção não tem a forma de um hype cycle do Gartner. Ela está se bifurcando. Os engenheiros seniores estão se afastando porque conseguem arquitetar o uso de ferramentas de IA. Os engenheiros juniores estão confusos porque pensam que a IA substitui o aprendizado — não substitui, apenas acelera o que você já sabe.
A Armadilha da Alavancagem
Aqui está a verdade desconfortável para engenheiros Staff+: a IA amplia sua carga de revisão mais rápido do que amplia sua produção. Se sua equipe de 6 engenheiros adotar ferramentas de codificação de IA, cada um gerará 30–50% mais pull requests. Isso representa 6x a carga de revisão adicional — e tudo flui para cima, em direção a você.
Antes da IA, você revisava 3–4 PRs substantivos por dia. Agora você revisa 5–7, cada um com modos de falha sutilmente diferentes: chamadas de API alucinadas, imports fantasmas, testes que passam localmente mas testam o comportamento errado. Seu calendário não cresceu. Sua fila de revisão cresceu.
Os engenheiros Staff+ que estão prosperando não estão revisando mais — eles estão revisando diferente:
- Revisões de arquitetura antecipadas (front-load): Gaste 15 minutos aprovando o design antes que a IA gere o código. Isso elimina 60% do retrabalho conceitual.
- Delegue a validação de padrões: Treine engenheiros de nível médio para detectar modos de falha específicos de IA (dependências fantasmas, artefatos de janela de contexto, desvio de estilo). Isso distribui a carga de revisão.
- Agrupe PRs gerados por IA em lotes: Revise todas as mudanças produzidas por IA em uma única sessão, em vez de intercalá-las com PRs humanos. Seu cérebro alterna menos o contexto e o reconhecimento de padrões entra em ação.
O Paradoxo da Mentoria
Há um custo mais sutil que ninguém menciona nas demos dos fornecedores: as ferramentas de IA corroem o pipeline de mentoria. Quando um engenheiro júnior escreve um boilerplate manualmente, ele aprende por que o padrão existe. Quando a IA o escreve, ele aprende que o padrão existe — uma forma de conhecimento muito mais fraca.
Daqui a dois anos, seu pipeline de Staff+ dependerá de engenheiros de nível médio que compreendam profundamente o design do sistema. Se esses engenheiros passaram seus anos formativos aceitando sugestões de IA sem entender os trade-offs subjacentes, você terá uma lacuna de talento que nenhuma ferramenta poderá preencher.
A correção? Estabeleça sessões de design "livres de IA", onde os engenheiros esboçam soluções em quadros brancos antes de tocar em qualquer ferramenta. Use IA para implementação, não para educação.
Parte 6: O Catálogo de Anti-padrões
Estes são os cinco erros organizacionais que destroem o ROI da produtividade de IA. Se você reconhecer algum, pare e corrija-o antes de adicionar mais ferramentas.
❌ Anti-padrão 1: A Implementação Baseada em Demos (Demo-Driven Rollout)
Sintoma: A liderança vê uma demo de 5 minutos de IA e exige a adoção em toda a empresa para o próximo trimestre.
Por que falha: Demos otimizam para o fator uau, não para a integração do fluxo de trabalho. O desenvolvedor que gerou um componente React em 30 segundos não mostrou os 45 minutos que passou depurando o array de dependências do useEffect que a IA errou.
Correção: Teste piloto com uma única equipe por 2 sprints. Meça as métricas DORA antes e depois. Deixe os dados apresentarem o caso de negócio.
❌ Anti-padrão 2: Linhas de Código como KPI
Sintoma: Painéis de métricas de engenharia mostram orgulhosamente que as "LoC impulsionadas por IA aumentaram 200%".
Por que falha: Mais código não é o mesmo que melhor código. Os dados da Faros mostram que os tamanhos dos PRs aumentam 154% com a adoção de IA — mas o tempo de revisão aumenta 91% e os bugs por desenvolvedor aumentam 9%. Você está fabricando complexidade.
Correção: Substitua LoC por taxa de falha de mudança e rotatividade de código (churn). Estes medem resultados, não volume.
❌ Anti-padrão 3: A Aposta na Janela de Contexto
Sintoma: Engenheiros colam bases de código inteiras em prompts de IA esperando que ela "descubra tudo".
Por que falha: As janelas de contexto têm limites rígidos (128K–200K tokens para os principais modelos em 2026). Mesmo dentro desses limites, a atenção degrada para tokens no meio da janela. É estatisticamente provável que você obtenha resultados piores com um prompt de 100K tokens do que com um prompt focado de 2K tokens com instruções claras.
Correção: Decomponha as tarefas em unidades atômicas. Um prompt por preocupação. Forneça apenas as interfaces, tipos e exemplos relevantes — não o monorepo inteiro.
❌ Anti-padrão 4: Pulando a Revisão para Código de IA
Sintoma: "A IA escreveu, e os testes passaram — pode enviar."
Por que falha: Os testes validam o comportamento esperado. O código gerado por IA frequentemente introduz problemas sutis que os testes existentes não cobrem: condições de corrida, mutações de estado implícitas, expansão da superfície de segurança ou contratos de API que quebram consumidores downstream. A taxa de vulnerabilidade de 87% em PRs gerados por IA não é um bug na IA — é uma lacuna no processo de revisão.
Correção: O código de IA recebe o mesmo rigor de revisão que o código humano. Ponto final. Na verdade, ele precisa de mais escrutínio porque o autor (a IA) não consegue explicar o seu raciocínio durante a revisão.
❌ Anti-padrão 5: Maximalismo de Ferramentas
Sintoma: A equipe usa Copilot, Cursor, Claude Code, Aider, Cody, um wrapper de GPT personalizado e três bots no Slack — tudo simultaneamente.
Por que falha: Cada ferramenta adiciona sobrecarga cognitiva: atalhos diferentes, modelos mentais diferentes, modos de falha diferentes. Alternar o contexto entre ferramentas consome mais tempo do que qualquer ferramenta individual economiza. E quando algo quebra, qual ferramenta introduziu o bug?
Correção: Escolha no máximo duas ferramentas — uma inline (editor) e uma agentic (terminal/background). Domine-as profundamente em vez de experimentar superficialmente. Reavalie trimestralmente.
O Roadmap Honesto
Aqui está o que realmente funciona para equipes que veem ganhos de velocidade sustentados:
- Meça o baseline (1 sprint): Métricas DORA, tempo de revisão de PR, taxa de escape de bugs, antes de qualquer nova ferramenta.
- Introduza as ferramentas gradualmente (1 sprint): Copilot ou Claude Code. Apenas isso. Sem agentes ainda.
- Instrumente tudo (contínuo): Acompanhe a taxa de falha de mudança, tamanho do PR, tempo de revisão por commit de IA vs. commit humano.
- Introduza agentes após ter dados (semana 8+): Depois de entender o gargalo, os agentes devem ser direcionados a esse gargalo.
- Aposente impiedosamente ferramentas de baixo impacto (trimestralmente): Se ela não moveu suas métricas, não está agregando valor — está apenas adicionando barulho.
As equipes que passaram de "sem IA" para o "caos agentic total" são as que relatam um impacto de produtividade negativo. As equipes que estão enviando código silenciosamente mais rápido são as que trataram a IA como infraestrutura: mediram-na com rigor, iteraram na integração e nunca confundiram a adoção de ferramentas com o resultado do negócio.
Fontes Externas
- Estudo de Impacto de IA da METR (2025–2026): https://metr.org/blog/2025-07-10-early-2025-ai-experienced-os-dev-study/
- Relatório do Paradoxo da Produtividade da Faros AI: https://www.faros.ai/blog/ai-software-engineering
- DX Core 4 Framework e Medição de IA: https://www.buildmvpfast.com/blog/dx-core-4-developer-productivity-measurement-ai-impact-2026/
- Rankings de Ferramentas de Dev de IA da LogRocket (março de 2026): https://blog.logrocket.com/ai-dev-tool-power-rankings/
- Estatísticas de Produtividade de Desenvolvedores com Ferramentas de IA: https://www.index.dev/blog/developer-productivity-statistics-with-ai-tools
Leituras Relacionadas no gsstk
- Engenharia de Software na Era da IA (Parte 1) — Aether, padrões fundamentais
- Como usar o Claude AI (Técnico) — Aether, estratégias profundas de prompting
- Engenharia de Software na Era da IA (Parte 2) — Aether, frameworks de governança
- A Tomada do CLI Agentic — Aether, fluxos de trabalho baseados em terminal
- 87% dos Seus Pull Requests Gerados por IA Têm Vulnerabilidades de Segurança — Icarus, o ponto cego da revisão de código