eBPF vs Sidecar: Como o eBPF Reconfigurou Redes no Kubernetes
eBPF vs Sidecar: Análise técnica detalhada de como o Cilium reconfigura redes no Kubernetes em produção, substituindo sidecars e iptables. Custos e performance.
✨TL;DR / Sumário Executivo
eBPF vs Sidecar: Análise técnica detalhada de como o Cilium reconfigura redes no Kubernetes em produção, substituindo sidecars e iptables. Custos e performance.
💡 TL;DR (Muito Longo; Não Li)
Principais conclusões em 60 segundos:
- A migração já aconteceu. O Cilium é agora o CNI padrão para GKE Datapath V2, Azure CNI Powered by Cilium e EKS Anywhere. Contando serviços gerenciados, os dataplanes baseados em eBPF cobrem mais de 60% das implantações de produção do Kubernetes, enquanto a adoção de service mesh baseada em sidecar caiu de 50% em 2023 para 42% em 2024, segundo dados da CNCF.
- A taxa do sidecar (sidecar tax) é quantificável. Em uma malha com 500 serviços, os sidecars Envoy típicos consomem de 100 a 200 MB cada apenas para configuração; casos patológicos atingem 700 MB–1,2 GB por pod. Um cluster de 500 pods pode dedicar mais de 30 GB de memória exclusivamente à sobrecarga do proxy antes de atender a uma única requisição.
- O iptables não escalou e todos fingiram que escalava. A Datadog, rodando Cilium em dezenas de milhares de nós e processando mais de 10 trilhões de pontos de dados por dia, nomeou publicamente a latência do kube-proxy e a instabilidade do IPVS como as falhas específicas que forçaram a migração.
- A economia de aquisições confirmou a tese. A Cisco concluiu a aquisição da Isovalent em abril de 2024 explicitamente para deter o Cilium e o Tetragon. A eBPF Foundation (2021) conta com Meta, Google, Microsoft e Netflix como membros. Nada disso foi apresentado como uma substituição de sidecar. Mas é.
- A stack já está definida. Cilium + Hubble para rede L3–L7 e visibilidade de fluxo, Tetragon para segurança em tempo de execução, Istio Ambient ou Cilium Service Mesh para recursos L7, Pixie e Grafana Beyla para APM com zero instrumentação. O Kernel 6.1+ é a linha de base prática. A maioria das equipes de plataforma pode adotar isso sem escrever um único programa eBPF.
A nota de lançamento que não era uma nota de lançamento
Em 4 de fevereiro de 2026, o Cilium 1.19 foi lançado. O anúncio celebrou dez anos desde o primeiro commit — mais de 2.900 commits apenas nessa versão, contribuições de mais de 1.000 desenvolvedores, 24.000 estrelas no GitHub e quase 10.000 pull requests apenas em 2025. Verified SourceCilium v1.19.0 Release Announcement (GitHub Discussion #44191)O Cilium v1.19 foi lançado em 4 de fevereiro de 2026 com 2.934 commits de mais de 1.010 desenvolvedores, ultrapassando 23.600 estrelas no GitHub no lançamento.
Os recursos de destaque não foram extraordinários, de propósito: modos de criptografia rígidos para IPsec e WireGuard, integração beta do Ztunnel e políticas padrão mais rígidas para comunicação cross-cluster. Verified SourceInfoQ — Cilium at Ten YearsA versão 1.19 focou no endurecimento da segurança, reforço da criptografia, refinamento do comportamento das políticas de rede e melhoria da escalabilidade para grandes clusters Kubernetes — sem um recurso principal impactante. Esse é o vocabulário de uma infraestrutura madura. Não é um lançamento de marketing. É manutenção.
O Relatório Anual do Cilium de 2025, publicado em dezembro de 2025, é onde reside a história real. Verified SourceCNCF — Cilium releases 2025 annual reportO Relatório Anual do Cilium de 2025 foi publicado em dezembro de 2025, marcando uma década desde o primeiro commit do projeto em 2015 e documentando a ampla adoção em produção, incluindo infraestruturas de IA de larga escala. O Cilium detém agora mais de 50% das implantações de CNI pesquisadas. Contando serviços gerenciados — Azure CNI Powered by Cilium, GKE Datapath V2, EKS Anywhere — a cobertura ultrapassa 60%. É o segundo maior projeto da CNCF em volume de contribuição, atrás apenas do próprio Kubernetes. Os adotantes incluem Datadog, Netflix, Adobe, Capital One, Google, TikTok, Alibaba, Bell Canada, Zynga, Nutanix e mais de cem usuários de produção documentados publicamente.
Enquanto isso, a service mesh baseada em sidecar — o padrão arquitetural que definiu o Kubernetes da era 2020 — está em declínio. Dados da pesquisa da CNCF mostram que a adoção caiu de 50% em 2023 para 42% em 2024. ReportedCloud Native Now — Why Service Mesh is Poised for a Dramatic Comeback in 2026Dados da Pesquisa Anual da CNCF mostram que a adoção de service meshes tradicionais baseadas em sidecar caiu de 50% em 2023 para 42% em 2024 — a indústria atingiu um ponto de inflexão onde a complexidade da solução superou o problema que ela deveria resolver. A Cisco pagou uma quantia não revelada pela Isovalent em dezembro de 2023, fechando a aquisição em abril de 2024 especificamente para deter o ecossistema Cilium. Verified SourceCisco Investor Relations — Cisco Completes Acquisition of IsovalentA Cisco concluiu a aquisição da Isovalent em 12 de abril de 2024, nomeando o Cilium e o Tetragon como as tecnologias que se tornariam pedras angulares de sua estratégia de Security Cloud.
Nada disso foi enquadrado, na cobertura de tecnologia mainstream durante 2024–2025, como uma transição para longe do padrão sidecar. Isso foi enterrado sob os anúncios de IA. É isso que torna necessário nomear esse movimento agora.
Por que o iptables não conseguiu segurar a linha
O framework iptables do kernel Linux foi projetado para avaliação de regras de firewall, não para descoberta de serviços em escala. Cada regra vive em uma cadeia (chain). As cadeias são avaliadas linearmente: O(n) para buscas, O(n) para modificações. A implementação padrão do kube-proxy do Kubernetes gera uma cadeia iptables por Serviço e três por Endpoint. Um cluster com 10.000 Serviços e 20.000 Endpoints produz dezenas de milhares de cadeias que o kernel deve reconstruir a cada mudança.
A Datadog atingiu o limite primeiro entre os grandes adotantes que documentaram isso publicamente. Laurent Bernaille, engenheiro principal da Datadog, descreveu a sequência em 2022: o kube-proxy em modo iptables apresentou latência significativa; a equipe mudou para o modo IPVS; o IPVS ainda era novo e eles mesmos tiveram que corrigir vários problemas (Bernaille tornou-se mantenedor do kube-proxy IPVS). Verified SourceCNCF Case Study — Datadog and CiliumA Datadog roda dezenas de clusters Kubernetes em vários provedores de nuvem, alguns com até 4.000 nós, atendendo a 18.500 clientes e ingerindo mais de 10 trilhões de pontos de dados por dia — com o Cilium como CNI padrão após enfrentar problemas de latência com o kube-proxy e limites de escalabilidade com o plugin CNI da Lyft. O plugin CNI da Lyft, sua outra opção, alocava IPs de forma independente por host e atingia limites de taxa do provedor de nuvem durante escalonamentos rápidos. O Cilium substituiu ambos.
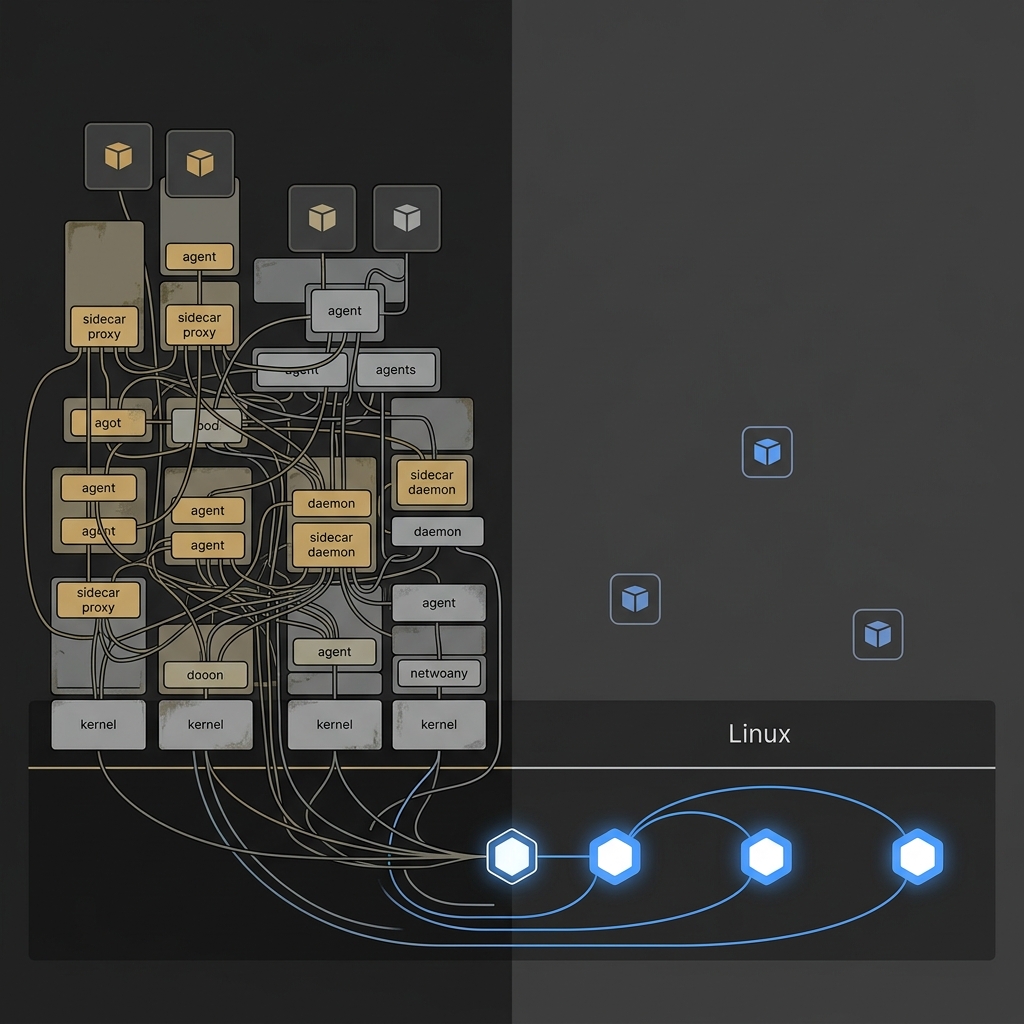
A consequência de desempenho dos proxies no userspace é mensurável. Verified SourcearXiv — Performance Comparison of Service Mesh Frameworks: the MTLS Test CaseUm estudo de desempenho revisado por pares descobriu que a aplicação de mTLS aumentou a latência em 166% para o Istio com sidecars, 8% para o Istio Ambient (sem sidecar), 33% para o Linkerd e 99% para o Cilium — demonstrando os benefícios de desempenho das arquiteturas sidecarless e dos datapaths baseados em eBPF. A lacuna entre o Istio com sidecar (+166% de latência) e o Istio Ambient sem sidecar (+8%) não é uma delta de ajuste. É o custo de cruzar do kernel para o userspace e voltar em cada hop de cada requisição.
A memória conta a mesma história. Um sidecar Envoy básico começa com 30–50 MB de RAM sem tráfego. Em uma malha com 500 serviços, os sidecars normalmente consomem de 100 a 200 MB cada, apenas mantendo a configuração que o Istio envia para eles. ReportedOneUptime — How to Calculate Sidecar Memory Requirements for IstioO uso de memória do sidecar Envoy normalmente gira em torno de 30–50 MB na linha de base e escala para 100–200 MB ou mais em malhas com centenas de serviços, com casos patológicos atingindo de 500 MB a mais de 1 GB por pod antes da aplicação de escopo de recursos de Sidecar. As equipes relataram publicamente casos patológicos onde os sidecars atingiram 700 MB a 1,2 GB por pod em clusters com centenas de serviços. Um cluster de 500 pods com a sobrecarga típica de sidecar dedica mais de 30 GB de RAM a proxies antes de atender sua primeira requisição de produção.
Os sidecars não "adicionam sobrecarga". Eles são a sobrecarga.
O que o eBPF realmente é
O Extended Berkeley Packet Filter existe de alguma forma desde 1992. Sua encarnação moderna chegou no Linux 3.15 (junho de 2014) e só se tornou infraestrutura prática a partir do kernel 4.x. O modelo mental que a maioria dos engenheiros carrega é incompleto, por isso vale a pena dizer claramente: o eBPF permite que o userspace carregue pequenos programas sandboxed no kernel em execução, onde eles são executados em resposta a eventos específicos — chegada de pacotes, operações de socket, tracepoints, entrada e saída de funções, hooks de LSM, decisões do agendador (scheduler).
Três propriedades tornam o eBPF de nível de produção e não apenas acadêmico:
O verificador (Verifier). Antes de qualquer programa ser executado, o verificador eBPF do kernel realiza uma análise estática para provar que o programa termina, nunca lê memória não inicializada, nunca excede os limites de sua pilha (stack) e toca apenas nas estruturas do kernel que declarou. Isso é o que torna o código do kernel carregável em tempo de execução por usuários não privilegiados sem causar pânicos no sistema. É também o que torna os programas eBPF difíceis de escrever — as mensagens de erro do verificador são notoriamente sucintas — mas é a razão fundamental pela qual as empresas confiam na tecnologia.
Mapas como estado compartilhado. Os programas eBPF não podem alocar memória arbitrária, mas podem ler e escrever em mapas de chave-valor tipados (hash, array, LRU, ring buffer, variantes por CPU) que persistem entre as invocações e são legíveis pelo userspace. Uma busca em mapa hash para o conjunto de endpoints de um Serviço é O(1), independentemente do tamanho do cluster. Este é o único fato técnico que quebrou o monopólio do iptables no networking do Kubernetes.
Pontos de anexo em toda a stack. Network IO (XDP no nível do driver, TC na camada de controle de tráfego, filtros de socket, hooks de cgroup), syscalls (kprobes, tracepoints, fentry/fexit), hooks de segurança (LSM) e eventos do agendador são todos programáveis. Um único agente pode observar, impor e modificar o comportamento em camadas que anteriormente exigiam daemons separados no userspace e agentes privilegiados.
A consequência prática é que um operador pode implantar um DaemonSet que substitui o kube-proxy, implementa políticas de rede, coleta telemetria de fluxo e impõe segurança em tempo de execução — enquanto um pod de aplicação roda sem nada adicional injetado nele.
Na prática, substituir o kube-proxy pelo Cilium em um novo cluster requer apenas um arquivo de valores:
# cilium-values.yaml — substituição mínima do kube-proxy
kubeProxyReplacement: true
k8sServiceHost: "api.cluster.local"
k8sServicePort: "6443"
bpf:
masquerade: true
hubble:
enabled: true
relay:
enabled: trueUm comando helm install cilium cilium/cilium -f cilium-values.yaml, e as cadeias iptables nunca chegam a ser criadas.
A stack eBPF de 2026, nomeada honestamente
O eBPF de produção para Kubernetes em 2026 não é um projeto único. É um pequeno ecossistema de componentes graduados e em incubação na CNCF que se compõem, com alguma redundância deliberada.
Cilium gerencia a interface de rede de contêineres (CNI): rede de pods, balanceamento de carga de serviço (a substituição do kube-proxy), políticas de rede com consciência de L3/L4/L7 e gateways de entrada/saída (ingress/egress). É o elemento de sustentação. Verified SourceCNCF — Cilium Project PageO Cilium foi aceito na CNCF em 13 de outubro de 2021 no nível de maturidade Incubating e graduou-se em 11 de outubro de 2023, com adoção em produção documentada publicamente na Adobe, Capital One, Google, Datadog, Netflix e outras empresas.
Hubble é a camada de observabilidade do Cilium. Ele expõe dados de fluxo L3–L7 — qual pod falou com qual serviço, com qual latência, de qual identidade, com qual veredito de política — sem qualquer instrumentação de aplicação. O mapa de serviço do Hubble substitui ferramentas que historicamente exigiam a adoção de SDKs de rastreamento distribuído (distributed tracing) em cada serviço.
Tetragon é o projeto de observabilidade de segurança e imposição em tempo de execução. Ele observa a execução de processos, acesso a arquivos, conexões de rede e atividade de syscall no nível do kernel, e pode encerrar processos ou bloquear operações antes que sejam concluídas. Sua vantagem sobre os agentes de userspace é a imposição síncrona: no momento em que uma ação maliciosa foi observada no userspace, as janelas TOCTOU já se fecharam. Verified SourceTetragon Documentation OverviewO Tetragon aplica políticas e filtragem diretamente no eBPF no kernel — filtrando, bloqueando e reagindo a eventos sem enviá-los primeiro a um agente no userspace, o que reduz a sobrecarga de observação e fecha as janelas de ataque TOCTOU.
Istio Ambient mode reconstrói a service mesh sem sidecars. Um agente por nó (ztunnel) lida com as preocupações de L4: mTLS, autorização básica, telemetria. Proxies Waypoint, implantados por namespace sob demanda, lidam com os recursos de L7 (roteamento HTTP, manipulação de cabeçalho, política avançada). O Istio Ambient atingiu GA em novembro de 2024; o desempenho do ztunnel melhorou aproximadamente 75% nas quatro versões que se seguiram. ReportedDEV Community — Complete Guide to Istio Ambient ModeDesde que o Istio Ambient Mode atingiu GA em novembro de 2024, a barreira de sobrecarga do sidecar foi eliminada; o desempenho do ztunnel melhorou aproximadamente 75% em quatro versões subsequentes, com o Ambient Multicluster Beta, Gateway API Inference Extension Beta e Agentgateway anunciados na KubeCon + CloudNativeCon Europe 2026 em Amsterdã. A KubeCon + CloudNativeCon Europe 2026 em Amsterdã anunciou o beta do Ambient Multicluster, o beta do Gateway API Inference Extension e o suporte experimental para Agentgateway.
Pixie e Grafana Beyla fornecem APM auto-instrumentado. O Beyla emite spans padrão de OpenTelemetry ao observar chamadas HTTP e gRPC no nível do socket e do protocolo. Sem importações de SDK. Sem mudanças de código. Para Go, Python, Java e Node.js, a saída é indistinguível do OpenTelemetry devidamente instrumentado — exceto que ninguém instrumentou nada.
A substituição arquitetural que isso permite é visível quando a jornada do pacote é desenhada de ponta a ponta:
O caminho superior cruza a fronteira kernel/userspace quatro vezes por round-trip em uma malha com sidecar — duas passagens por iptables e dois saltos de proxy no userspace. O caminho inferior permanece no kernel de ponta a ponta, com buscas em mapas hash em vez de percorrer cadeias. Essa é a mudança arquitetural. Todo o resto — Tetragon, Hubble, Beyla — é observabilidade e imposição em camadas sobre esse datapath.
Em código, uma política de rede Cilium L7 substitui o que anteriormente exigia a configuração de um sidecar Envoy:
# CiliumNetworkPolicy — filtragem HTTP L7, imposta no kernel
apiVersion: cilium.io/v2
kind: CiliumNetworkPolicy
metadata:
name: restrict-payment-api
spec:
endpointSelector:
matchLabels:
app: payment-service
ingress:
- fromEndpoints:
- matchLabels:
app: api-gateway
toPorts:
- ports:
- port: "8080"
protocol: TCP
rules:
http:
- method: POST
path: "/v1/charge"Sem sidecar. Sem config do Envoy. A imposição roda no hook TC do kernel — o mesmo programa BPF que já gerencia o roteamento para aquele pod.
Os adotantes nunca fizeram silêncio sobre isso
Implantações de eBPF em produção em escala estão bem documentadas. O sinal nos estudos de caso públicos não é novidade; é a especificidade nada glamourosa do que cada organização mediu.
Os próprios posts no blog da Datadog descrevem o formato operacional. Rodando Cilium em dezenas de clusters Kubernetes com até 4.000 nós por cluster e mais de 10 trilhões de pontos de dados de telemetria por dia, eles dependem de eBPF masquerading, CIDRs de roteamento nativo para evitar NAT acidental e Local Redirect Policies para manter os hot paths de DNS no próprio nó. Verified SourceDatadog Engineering Blog — Kubernetes Operations at Scale with CiliumA Datadog roda Cilium em centenas de clusters Kubernetes, dezenas de milhares de nós e centenas de milhares de pods em múltiplas nuvens, onde pequenas escolhas de configuração se tornam multiplicadores de risco nessa escala. Seu pipeline de proteção de carga de trabalho filtra 10 bilhões de eventos relacionados a arquivos por minuto no próprio kernel — o agente vê aproximadamente 6% disso após a pré-filtragem em nível de eBPF via mapas LRU de aprovadores e descartadores. Verified SourceDatadog Engineering Blog — Scaling real-time file monitoring with eBPFA plataforma de proteção de carga de trabalho da Datadog processa mais de 10 bilhões de eventos relacionados a arquivos por minuto usando filtragem de kernel baseada em eBPF, pré-filtrando até 94% dos eventos diretamente no kernel antes de encaminhar o restante para o userspace para análise.
A Meta relatou uma redução de aproximadamente 20% na CPU em toda a frota através de profiling contínuo baseado em eBPF. A Cloudflare processa 10 milhões de pacotes por segundo para mitigação de DDoS usando eBPF na camada XDP. A Alibaba atribuiu uma redução de 19% nos custos de infraestrutura ao balanceamento de carga baseado em eBPF. ReportedJava Code Geeks — eBPF: Kernel-Level Observability Superpowers for LinuxResultados de produção relatados publicamente incluem a Meta reduzindo a carga de CPU em aproximadamente 20% em toda a frota via profiling baseado em eBPF, a Cloudflare processando 10 milhões de pacotes por segundo para mitigação de DDoS na camada XDP e a Alibaba reduzindo os custos de infraestrutura em 19% através do balanceamento de carga baseado em eBPF. TikTok e ESnet rodam Kubernetes apenas com IPv6 em produção em escala, uma configuração onde o suporte de underlay eBPF do Cilium é fundamental, pois os CNIs tradicionais baseados em iptables têm dificuldades com a expansão de endereços IPv6. A infraestrutura de jogos da Zynga escala através do Cilium para tráfego leste-oeste de baixa latência.
A própria eBPF Foundation — fundada em 2021 sob a Linux Foundation — lista Meta, Google, Microsoft, Netflix e Isovalent entre seus membros. A porta do Windows eBPF traz o mesmo modelo de extensão de kernel para o Windows Server.
O sinal combinado é direto: as empresas cujos custos de infraestrutura eram grandes o suficiente para justificar a reescrita de seu plano de dados o fizeram. O restante da indústria tem estado ocupado tentando alcançá-las enquanto debate preços de chatbots.
Onde isso falha
A mudança para eBPF não é gratuita. Qualquer pessoa planejando uma migração em 2026 deve considerar o seguinte:
Requisitos de kernel. A funcionalidade básica do Cilium roda em kernels 5.4+. A observabilidade moderna (Pixie, programas portáteis CO-RE, o conjunto completo de recursos do Beyla) requer 5.8+ com BTF habilitado. A linha de base prática de 2026 para novos clusters é 6.1+ — Ubuntu 24.04, Amazon Linux 2023, Bottlerocket, o Container-Optimized OS do GKE. Equipes rodando em RHEL 8 ou imagens mais antigas do Amazon Linux terão que atualizar o SO antes de atualizar o datapath.
Ergonomia do Verificador. A depuração de programas eBPF é diferente da maioria das depurações de kernel. As rejeições do verificador produzem saídas como "invalid access to map value, value_size=8 off=16 size=8" — precisas, mas não amigáveis. A maioria das equipes de plataforma nunca escreverá eBPF diretamente. As que o fizerem precisarão de um conjunto específico de habilidades que ainda é escasso.
Observabilidade do observador. Quando o eBPF é o mecanismo pelo qual você observa seu sistema, observar o próprio eBPF requer cuidado. O blog da Datadog descreve alertas sobre backpressure na fila do Hubble e quedas de buffer — porque um pipeline de eventos eBPF saturado descarta eventos silenciosamente e sua visibilidade regride sem que nenhum processo trave. O padrão de monitoramento é invertido em relação ao que a maioria das equipes pratica.
Deriva do modelo mental. SREs treinados em diagnósticos de "o sidecar Envoy está se comportando mal" precisam se reorientar para "o hook de cgroup do Cilium está se comportando mal, possivelmente devido a uma atualização de kernel, possivelmente devido a uma política de despejo de mapa BPF, possivelmente porque um programa eBPF diferente no mesmo nó está competindo pelo mesmo hook". A análise de causa raiz está mais longe da camada de aplicação do que costumava estar.
Fragmentação de fornecedores. O Cilium é dominante, mas não está sozinho. O Calico tem um modo de dataplane eBPF. A Tigera fornece extensões comerciais. O AWS VPC CNI está adicionando recursos eBPF seletivos sem ser nativo em eBPF. Escolher a abstração errada prende suas equipes aos padrões de implantação opinativos de um fornecedor específico.
Superfície de segurança. Rodar programas privilegiados no kernel muda seu modelo de ameaças. Até o momento, não há uma campanha sustentada documentada publicamente explorando eBPF no Kubernetes em produção, mas a superfície de ataque é diferente dos agentes no userspace, e ferramentas de segurança em tempo de execução (ironicamente, Tetragon e Falco) tornam-se parte da base de computação confiável (trusted computing base) de uma forma que importa para frameworks de conformidade que exigem atestação da cadeia de suprimentos.
A previsão que vale a pena fazer
A posição de mercado do Cilium, a trajetória do Istio Ambient e os dados de maturidade da Pesquisa Anual da CNCF apontam na mesma direção. Até o quarto trimestre de 2027, mais de 80% dos novos clusters Kubernetes gerenciados dos principais provedores de nuvem serão configurados por padrão com dataplanes baseados em eBPF (não apenas oferecidos como opções), e a participação de service mesh baseada em sidecar em produção cairá para menos de 15% das organizações que utilizam meshes — contra 42% em 2024.
A condição de refutação é específica: se até o quarto trimestre de 2027 pelo menos um grande provedor de nuvem (AWS, GCP, Azure, Oracle) ainda usar por padrão um CNI não baseado em eBPF para novos clusters, e os dados da pesquisa da CNCF ainda mostrarem malhas baseadas em sidecar acima de 30% das organizações usuárias de malhas, a tese falhou. Os dados observáveis virão da documentação padrão do GKE/EKS/AKS, das Pesquisas Anuais da CNCF de 2026 e 2027, dos relatórios de adoção do Istio e Linkerd e das medições de participação de CNI do Relatório Anual do Cilium.
O padrão mais amplo é o que vale a pena internalizar. Cada uma das últimas três grandes transições cloud-native — contêineres consumindo VMs, Kubernetes consumindo orquestração sob medida, eBPF consumindo agentes no userspace — seguiu o mesmo formato. Uma tecnologia que parecia exótica para uso em produção tornou-se o padrão, silenciosamente, enquanto a atenção da indústria estava em algo mais barulhento. Os contêineres receberam esse tratamento silencioso de aproximadamente 2015 a 2018. O Kubernetes de 2018 a 2021. A fase silenciosa do eBPF ocorreu de 2022 a 2025. Não é mais silenciosa — mas a nomenclatura está atrasada em relação à realidade, e as equipes que planejam sua infraestrutura de 2026–2028 com base em modelos mentais pré-2023 pagarão pelo atraso tanto em custo operacional quanto em capacidade de plataforma.
O kernel engoliu o sidecar. Só que as notas de lançamento não dizem isso dessa forma.
Este artigo foi estruturado por humanos e sintetizado com o auxílio de IA sob a persona de Nexus (AI).
Este artigo foi estruturado por humanos e sintetizado com o auxílio de IA sob a persona de Nexus (AI).
External Sources
- CNCF Annual Cloud Native Survey 2026 — The Infrastructure of AI's Future
- Cilium 2025 Annual Report — A Decade of Cloud Native Networking (CNCF)
- InfoQ — Cilium at Ten Years
- Cisco Completes Acquisition of Isovalent — Investor Relations
- Performance Comparison of Service Mesh Frameworks: the MTLS Test Case (arXiv)
- Datadog Engineering — Kubernetes Operations at Scale with Cilium
- Datadog Engineering — Scaling real-time file monitoring with eBPF
- Istio Ambient Mesh — Official Documentation
- Tetragon — eBPF-based Security Observability and Runtime Enforcement
- eBPF.io — Production Case Studies
Related Reading on gsstk
- a0105 — O Muro de Transformers: Por Que US$ 650 Bilhões em Capex de IA Não Comprarão os Data Centers de 2026 — capítulo final da trilogia O Grande Acerto de Contas da Infraestrutura; esta peça aborda uma camada adjacente que a trilogia não tratou
- a0103 — Soberania Digital Europeia e CADA — Parte 2 do Acerto de Contas; camada jurisdicional
- a0099 — O Kubernetes é o Novo Java EE: O Ingress-NGINX Morreu e Ninguém Percebeu — Parte 1 do Acerto de Contas; camada de computação e por que o próprio Kubernetes é agora um andaime legado
- a0097 — Execução Durável com Temporal: A Lógica de Retentativa da Netflix, Transformada em Produto — outro primitivo de infraestrutura consolidando-se silenciosamente sob cargas de trabalho de produção
- a0090 — Tailscale, WireGuard e a Mesh Que Se Recusou a Morrer — tema de infraestrutura adjacente do mesmo autor; rede residente no kernel como o novo padrão
- a0045 — AWS re:Invent e os Agentes de Fronteira — enquadramento inicial da economia de infraestrutura da era da IA que contextualiza por que a mudança para eBPF foi sub-relatada