eBPF é horrível de escrever. O KernelScript quer resolver isso.
O KernelScript unifica a criação de eBPF, userspace e módulos de kernel em uma única DSL segura de tipo. O modelo do compilador, a comparação antes/depois...
✨TL;DR / Sumário Executivo
O KernelScript unifica a criação de eBPF, userspace e módulos de kernel em uma única DSL segura de tipo. O modelo do compilador, a comparação antes/depois...
💡 TL;DR (Too Long; Didn't Read)
Destaques em 75 segundos:
- O atrito na criação de eBPF é estrutural, não incidental. O verificador, os alvos de compilação C divididos, o ciclo de vida manual de mapas e o carregador userspace separado se acumulam. O custo é arquitetural.
- KernelScript é uma linguagem de domínio específico em estágio beta criada por Cong Wang (Multikernel Technologies) que unifica o desenvolvimento de eBPF, userspace e módulos de kernel em um único arquivo
.ksusando uma única linguagem segura de tipos.- O mecanismo é a compilação guiada por atributos. As funções
@xdpe@tcgeram código C de eBPF seguro para o verificador; funções comuns geram C para o userspace;@kfuncgera C para módulos de kernel — tudo a partir de um único arquivo-fonte.- A aposta sobre o verificador reside nos tipos. O KernelScript utiliza arrays de largura fixa e tipos simplificados projetados para compatibilidade com o verificador, evitando explicitamente as estruturas genéricas que fazem o Rust produzir código rejeitado pelo verificador.
- O antes e o depois é palpável: um filtro XDP para descarte de pacotes grandes e seu carregador enxugam de três arquivos separados para um único arquivo
.ks. O sistema de tipos impede oattach()antes do sucesso doload()em tempo de compilação.- O veredito de produção é claro: beirando as 300 estrelas nas primeiras horas do anúncio OSS, 478 commits, licença Apache-2.0, aviso explícito de beta no README — trata-se de uma bancada experimental, não de um substituto direto para eBPF em produção.
- O sinal arquitetural é legítimo. A abstração em nível de linguagem sobre APIs de extensão de kernel está estruturalmente atrasada. Quer o KernelScript seja a resposta definitiva ou apenas uma prova de conceito, o problema que ele aponta é real.
Se você já escreveu programas eBPF — eBPF real em produção, não aquele tutorial simples de SEC("xdp") que descarta tudo —, conhece bem esse sentimento. Você escreve um código C aparentemente razoável. Compila com clang -target bpf. O verificador o rejeita. A mensagem de erro não diz nada de útil. Você passa uma hora lendo o código-fonte do kernel. Descobre que a aritmética de ponteiros na linha 34 tecnicamente sai do intervalo verificado, embora isso nunca ocorra na prática. Você faz o patch. O verificador aceita. Três semanas depois, você está de volta ao mesmo ciclo com outro programa.
Isso não é um problema de habilidade. É um problema de atrito enraizado na forma como os programas eBPF são escritos hoje. Cong Wang, colaborador do kernel Linux com dezesseis anos de experiência e mantenedor do subsistema de controle de tráfego de rede (TC) desde 2017, apresentou uma resposta proposta no Open-Source Summit da Linux Foundation em Minnesota na semana passada: o KernelScript. Trata-se de uma linguagem de domínio específico que compila um único arquivo-fonte em C para eBPF, C para userspace e C para módulos de kernel simultaneamente. Está em estágio beta. Não está pronto para produção. Vale a pena entender.
O custo de desenvolvimento do eBPF: o que ele realmente cobra
Escrever um programa XDP mínimo, mas realista, em C puro hoje significa gerenciar pelo menos três frentes distintas que residem em arquivos diferentes, compilados por ferramentas diferentes, com restrições diferentes.
O programa executado no kernel é um código C que se parece com C, mas não é. Você está escrevendo para a máquina virtual eBPF, não para um processador comum. O verificador — um analisador estático integrado ao kernel que roda antes de qualquer programa ser executado — impõe um subconjunto rígido de comportamentos do C. Cada acesso a ponteiro precisa ter seus limites checados antes do uso, caso contrário o verificador rejeitará o programa. Isso não é opcional e não é configurável: o verificador é todo o modelo de segurança para rodar código não confiável no espaço de kernel, e ele tende fortemente à rejeição.
As formas específicas de rejeição são pedagógicas. Você não pode ter laços infinitos ou indeterminados. Não pode desreferenciar um ponteiro sem antes provar à satisfação do verificador que ele está dentro de um intervalo válido. Não pode usar variáveis globais na maioria dos contextos. Não pode passar ponteiros arbitrários entre programas eBPF. Os metadados BTF (BPF Type Format) que codificam a estrutura de structs devem corresponder exatamente ao kernel em execução, caso contrário seu acesso seguro à struct vira comportamento indefinido em uma camada onde comportamento indefinido derruba a máquina.
O programa no lado do userspace é um C que parece C e na maior parte é C, exceto que também atua como código de cola. Ele abre o arquivo .o compilado com bpf_object__open_file(). Carrega o objeto com bpf_object__load(). Encontra o programa pelo nome com bpf_object__find_program_by_name(). Obtém um descritor de arquivo com bpf_program__fd(). Associa esse descritor a uma interface de rede usando bpf_xdp_attach(). Configura um buffer circular ou array de eventos perf para ler a saída vinda do kernel. Trata o encerramento por sinais. Gerencia os descritores de arquivo dos mapas BPF compartilhados entre os dois lados.
Nada disso é conceitualmente complexo. É, contudo, um boilerplate tedioso que precisa ser escrito corretamente, ou seu programa no kernel falhará silenciosamente ao carregar, falhará ao associar-se ou se associará ao gancho errado. Não existe verificação estática de tipos entre a definição do mapa no kernel e o acesso a esse mapa no userspace — eles precisam concordar por convenção, não por imposição do compilador.
Se você também precisa de kfuncs — funções exportadas pelo kernel que permitem ao seu programa eBPF chamar código de kernel personalizado além do conjunto padrão de auxiliares BPF —, passa a gerenciar um terceiro artefato: um módulo de kernel que precisa ser compilado, carregado e registrado com BTF antes que seu programa eBPF possa utilizá-lo. O sistema de build para isso é separado tanto da compilação eBPF quanto do build do userspace. Você agora gerencia três Makefiles.
A descrição de Cong Wang no OSS 2026 foi direta. Escrever eBPF é "horrível". Isso não é um argumento de marketing. É um diagnóstico de engenharia.
O Antes e o Depois
O exemplo mínimo canônico para filtragem de pacotes XDP — descartar pacotes maiores que 1500 bytes — ilustra o problema com clareza. No modelo em C puro + libbpf, você precisa de dois arquivos e um passo de build que conheça ambos.
O programa do lado do kernel:
// xdp_drop_large.bpf.c — compilado com clang -target bpf -O2
#include <linux/bpf.h>
#include <bpf/bpf_helpers.h>
SEC("xdp")
int xdp_drop_large(struct xdp_md *ctx) {
void *data_end = (void *)(long)ctx->data_end;
void *data = (void *)(long)ctx->data;
if (data_end - data > 1500)
return XDP_DROP;
return XDP_PASS;
}
char _license[] SEC("license") = "GPL";O carregador no userspace — abreviado aqui, mas a versão completa chega a dezenas de linhas quando o tratamento de sinais e a limpeza são incluídos:
// xdp_loader.c — compilado com clang, linka com libbpf
#include <bpf/libbpf.h>
#include <net/if.h>
#include <linux/if_link.h>
int main(int argc, char **argv) {
struct bpf_object *obj;
struct bpf_program *prog;
int prog_fd, ifindex;
obj = bpf_object__open_file("xdp_drop_large.bpf.o", NULL);
if (!obj) { /* tratamento de erro */ }
bpf_object__load(obj);
prog = bpf_object__find_program_by_name(obj, "xdp_drop_large");
prog_fd = bpf_program__fd(prog);
ifindex = if_nametoindex(argv[1]);
bpf_xdp_attach(ifindex, prog_fd, XDP_FLAGS_UPDATE_IF_NOEXIST, NULL);
pause(); /* aguarda sinal */
bpf_xdp_detach(ifindex, XDP_FLAGS_UPDATE_IF_NOEXIST, NULL);
bpf_object__close(obj);
return 0;
}E um Makefile que saiba chamar clang -target bpf para o primeiro arquivo e uma compilação C comum para o segundo.
O equivalente em KernelScript — de acordo com a sintaxe documentada no repositório:
// drop_large.ks — arquivo único, compilação única
@xdp fn drop_large_packets(ctx: *xdp_md) -> xdp_action {
var packet_size = ctx->data_end - ctx->data
if (packet_size > 1500) {
return XDP_DROP
}
return XDP_PASS
}
fn main() {
var prog = drop_large_packets.load()
prog.attach("eth0")
}Apenas um arquivo. O atributo @xdp informa ao compilador do KernelScript que drop_large_packets is um programa XDP — devendo gerar código C para eBPF com as restrições de tipo compatíveis com o verificador aplicadas. A função main() não é decorada, logo gera o código C de userspace com as chamadas de carregador libbpf correspondentes. O compilador gerencia o tempo de vida dos descritores de arquivo, a geração do BTF e a coordenação do ciclo de vida. Você não precisa escrever isso.
As propriedades de segurança para o verificador no C de eBPF gerado são cuidadas pelo sistema de tipos do KernelScript, e não por você inserindo verificações manuais de limites. Essa é a aposta estrutural que a linguagem faz: se o sistema de tipos for desenhado com foco na compatibilidade com o verificador desde o início, o C gerado deve passar no verificador com confiabilidade muito maior do que o C escrito à mão.
Como funciona o modelo do compilador
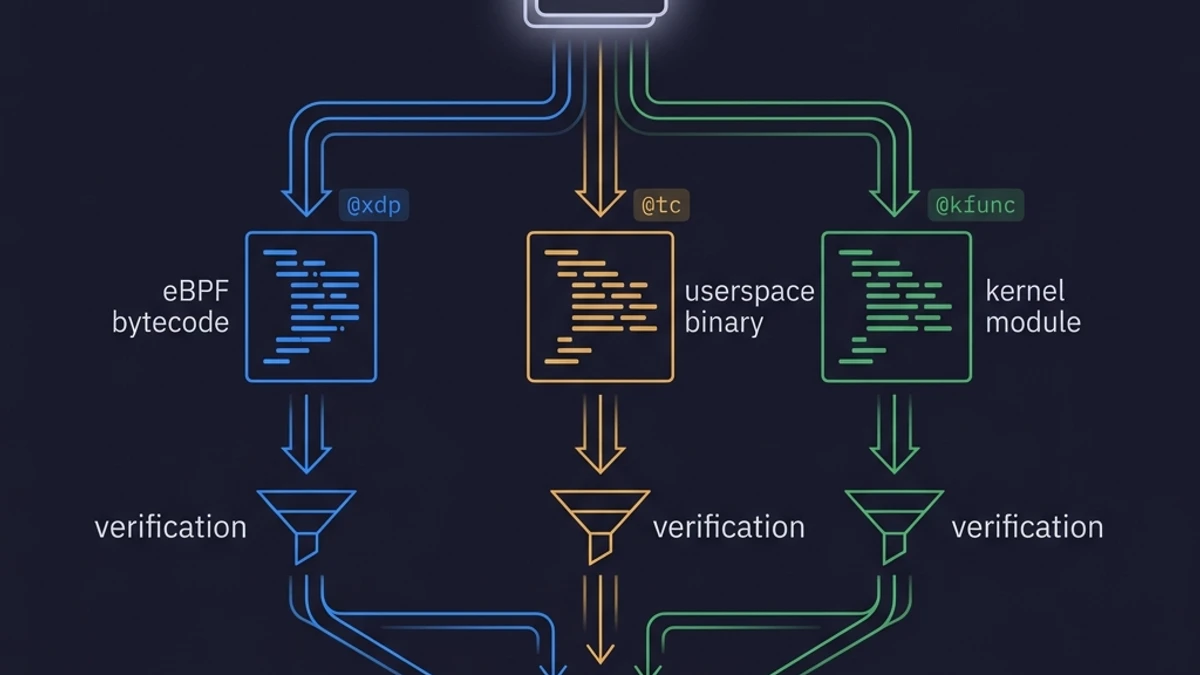
A abordagem de arquivo único e múltiplos alvos é a principal decisão de design do projeto, e vale a pena compreendê-la com precisão antes de avaliar se é a escolha certa.
O compilador inspeciona a decoração de atributos de cada função e a direciona para a rota correta de geração de código. As funções @xdp e @tc geram C para eBPF contendo as restrições que o verificador exige. As funções @kfunc geram C para módulos de kernel com o registro de símbolos BTF que as torna chamáveis a partir do eBPF. Funções sem decorações geram C para o espaço de usuário com a estrutura do libbpf necessária para carregar, associar e gerenciar o ciclo de vida dos programas eBPF descritos no mesmo arquivo.
Mapas — as estruturas de dados compartilhadas que permitem a comunicação entre o código no kernel e o código no userspace — são declarados uma única vez e compartilhados implicitamente entre todos os programas do arquivo. No modelo em C puro, a definição do mapa reside no arquivo C do eBPF e o código userspace o acessa pelo nome usando bpf_object__find_map_by_name(). No KernelScript, o mapa é uma declaração de primeira classe visível para todas as funções do arquivo, e o compilador gera a sintaxe de acesso adequada para cada alvo.
A história das tail calls é semelhante. No C eBPF cru, chamar outro programa eBPF de dentro de um programa requer a configuração de um mapa do tipo array de programas BPF, populá-lo no carregamento e chamar explicitamente bpf_tail_call() com o índice correspondente. No KernelScript, escrever return other_xdp_function(ctx) em uma função @xdp gera automaticamente a engrenagem de tail calls. O compilador monitora quais programas devem compor o array de programas e gera o código de inicialização do userspace condizente.
Essa é a promessa de ergonomia: o boilerplate é estrutural, logo pode ser gerado automaticamente.
Segurança de tipo no limite do verificador
O argumento de compatibilidade com o verificador é o aspecto mais interessante tecnicamente do design do KernelScript, e requer alguma precisão na análise.
O verificador realiza uma interpretação abstrata do seu programa. Ele rastreia o tipo e a faixa de valores de cada variável em cada instrução. Quando ele não consegue provar que um acesso de ponteiro está dentro dos limites de segurança, ele rejeita o programa. Quando o tipo de um valor difere do que uma função auxiliar espera, ele rejeita o programa.
O problema com o Rust como linguagem de criação para eBPF — sendo o Rust a comparação mais evidente dada a sua reputação de segurança de tipos — é que seu sistema de tipos não foi projetado tendo em mente as limitações do verificador. Os genéricos do Rust geram códigos que dependem de decisões de monomorfização tomadas em tempo de compilação. Essas decisões podem produzir tipos que a interpretação abstrata do verificador não consegue validar como seguros. O tratamento de erros com Result<T,E> no Rust gera padrões que não coincidem com os códigos de erro do tipo inteiro no estilo C do eBPF. Cadeias complexas de iteradores geram grafos de fluxo de controle que o verificador, o qual possui um limite rígido de instruções verificadas por programa, pode acabar rejeitando.
O KernelScript faz uma aposta diferente: em vez de uma linguagem de uso geral adaptada após o fato, ele desenha o sistema de tipos desde o início pensando no que o verificador é capaz de aceitar. Arrays de largura fixa em vez de fatias (slices) redimensionáveis dinamicamente. Códigos de erro inteiros em vez de tipos soma. Fluxo de controle simplificado em vez de encadeamento de iteradores. A linguagem aceita um orçamento de expressividade de tipos mais restrito em troca de uma maior probabilidade de que o código gerado passe no verificador.
Há uma garantia adicional fornecida pelo sistema de tipos que nada tem a ver com o verificador: ele impede que você execute o attach() antes do sucesso do load(). Isso parece trivial até que você depure uma condição de corrida em que o programa userspace tentou associar um programa cuja compilação ou carregamento anterior havia falhado. O sistema de tipos torna isso um erro em tempo de compilação em vez de causar um pânico em tempo de execução.
O que o sistema de tipos não entrega: ele ainda não consegue expressar toda a variedade de tipos de programas eBPF, tipos de mapas e interações de funções auxiliares usados por sistemas em produção. A linguagem está em estágio beta. A cobertura de tipos será expandida. Avaliá-la pelo que ela ainda não faz é o enquadramento errado — o ângulo correto é se a decisão arquitetônica de tornar a segurança de tipos um requisito de design de primeira classe é sólida. E ela é.
Quem desenvolveu e por que as credenciais importam
Cong Wang não é um designer de linguagens fazendo suposições sobre as entranhas do kernel. Ele é um desenvolvedor do kernel, e as escolhas de design no KernelScript refletem essa vivência.
Verified Sourcemultikernel.io/aboutCong Wang has sixteen years of Linux kernel development experience and has maintained the networking traffic control subsystem since 2017, with over 1,000 merged kernel commits. Prior to founding Multikernel Technologies, he led a software engineering team at ByteDance.Essa bagagem é importante por dois motivos principais. Primeiro, o subsistema de controle de tráfego é uma das áreas que mais usam eBPF em toda a pilha de rede do Linux — o tipo de programa tc-BPF é vital para o modo como ferramentas como o Cilium implementam políticas de saída (egress), limitação de largura de banda e marcação de pacotes. Wang escreveu e revisou mais C eBPF do que a maioria dos engenheiros verá na vida. Quando ele afirma que escrever eBPF é terrível, não está levantando um ponto de acessibilidade ou facilidade de uso. Ele está trazendo um argumento de custo de engenharia pautado em experiência prática direta.
Segundo, o design de uma linguagem para um alvo restrito como o verificador eBPF ganha muito quando há conhecimento íntimo de como o verificador opera por dentro. Os modos de falha do Rust-para-eBPF não são problemas teóricos; são padrões que um mantenedor do kernel enfrenta depurando rejeições de verificadores no dia a dia. As opções de design no KernelScript — arrays de largura fixa, ausência de genéricos, fluxo de controle simplificado — se comportam mais como uma resposta a uma taxonomia real de falhas do que como uma predileção teórica.
Reportedphoronix.comPhoronix covered the KernelScript presentation at the Linux Foundation's Open-Source Summit 2026 (Minnesota), noting that Wang explicitly described eBPF as miserable to write and framed KernelScript as targeting both eBPF programs and kernel extension development in a unified type-safe DSL.O projeto é público no GitHub sob o repositório multikernel/kernelscript. Em 24 de maio de 2026 — data da cobertura do Phoronix —, o repositório beirava as 300 estrelas ao longo de 478 commits, uma curva de atração que, no dia de uma palestra técnica, reflete a busca real da comunidade de desenvolvimento do kernel por esse tipo de abstração.
O veredito Staff+: o que é possível e o que não é possível fazer com isso
Sejamos exatos sobre o significado de "beta" no contexto de ferramentas que operam junto ao kernel.
Na maior parte dos contextos de software, "beta" equivale a "funcionalidades completas, alguns ajustes pendentes, prossiga com cuidado". No README do KernelScript, o aviso de beta carrega uma informação mais severa: "A sintaxe da linguagem, APIs e funcionalidades estão sujeitas a alterações a qualquer momento, sem garantia de retrocompatibilidade. Este software é destinado para uso experimental e feedback inicial. O uso em produção não é recomendado no momento." Isso não é uma isenção padrão de responsabilidade. É uma declaração técnica objetiva: o compilador pode sofrer mudanças de um jeito que silenciosamente altere o comportamento lógico dos programas criados hoje.
Para eBPF em produção — programas encarregados de impor regras de tráfego de rede, realizar observabilidade crítica ou prover controles de segurança em sistemas ativos —, essa é uma barreira severa, não um mero detalhe. Você não quer que sua regra de descarte XDP mude de comportamento entre versões de compilador em uma atualização não planejada. Não quer que a convenção de chamada do kfunc varie a ponto de produzir bugs em produção em vez de alertas de compilação. O verificador eBPF até capturará parte dessas falhas no carregamento do programa, mas não a totalidade delas.
O que você pode fazer com o KernelScript hoje:
Experimentos e aprendizado. O modelo de arquivo único simplifica bastante o entendimento da relação entre o código eBPF rodando no kernel e a camada de userspace. Se você está aprendendo eBPF e a verbosidade do libbpf esconde o conceito central do sistema, o KernelScript elimina esse ruído. Rode em uma máquina virtual de desenvolvimento. Analise o C gerado.
Ferramentas internas de baixo impacto (blast radius). Se você está montando ferramentas de monitoramento — uma sonda (probe) customizada ou um exportador de ring-buffer — em um ambiente controlado onde a versão do compilador pode ser travada e testada de antemão, o ganho de ergonomia é indiscutível. Escreve-se muito menos código, e o ciclo de vida dos recursos é gerido pela própria ferramenta.
Avaliação de soluções arquitetônicas. O KernelScript adota uma postura arquitetônica bem definida: compilação direcionada por atributos, arquivo único, múltiplos alvos e tipos mapeados para o verificador. Se você cogita criar ferramentas internas que abstraiam o eBPF para seu time de plataforma, vale a pena estudar a abordagem, mesmo que não venha a usá-la diretamente.
O que você não deve fazer com o KernelScript hoje: colocá-lo no caminho crítico de um cluster Kubernetes em produção, usá-lo para programas de reforço de segurança ativa ou integrá-lo em uma esteira de CI/CD sem congelar estritamente as versões envolvidas. A licença Apache-2.0 resguarda seus direitos, mas o termo de beta alerta onde mora o custo real.
O KernelScript não representa a primeira investida sobre esse problema — o bpftrace o tratou no campo de rastreamento, o Aya para o ecossistema Rust e o BCC para observabilidade guiada por Python. Cada uma resolveu uma fração e deixou o restante de lado. O que o KernelScript propõe — uma linguagem comum que unifique a criação de eBPF, userspace e módulos de kernel com restrições de tipos em todas as três fronteiras simultaneamente — é mais ousado do que as iniciativas anteriores, e o seu arquiteto dedicou dezesseis anos precisamente ao subsistema de kernel mais afetado pelo escopo.
A reflexão para engenheiros Staff+ não é sobre adotar a ferramenta agora ou não. É se a dor estrutural que ela endereça — o fato de que codificar em C cru para eBPF é custoso demais para as demandas crescentes do mercado — já foi incorporada ao planejamento de sua plataforma. O A0106 estabeleceu que caminhos de dados baseados em eBPF já cobrem mais de 60% dos ambientes Kubernetes em produção. As ferramentas de autoria ainda não acompanharam essa evolução. O KernelScript, com 478 commits em ritmo ativo de desenvolvimento, desponta como um primeiro vislumbre de que isso pode mudar.
Fontes Externas
- KernelScript — Repositório GitHub, multikernel/kernelscript — Fonte primária para sintaxe da linguagem, premissas de design e termo de beta.
- Multikernel Technologies — Sobre Cong Wang — Histórico verificado sobre a trajetória e as credenciais do mantenedor do kernel.
- Cobertura do KernelScript — Phoronix, 24 de maio de 2026 — Contexto de apresentação no OSS 2026 e a fala de Wang caracterizando o atrito na autoria do eBPF.
Leituras Recomendadas no gsstk
- O Kernel engoliu o Sidecar: eBPF reconfigurou o Kubernetes em produção (a0106) — Antecessor direto: o artigo que apontou o ecossistema eBPF como padrão de produção e registrou a carga operacional que o KernelScript tenta reduzir.
- O que é um Harness, afinal? Um testador de regressão para ferramentas LLM (a0108) — A importância de desenvolver e testar localmente seus recursos e apenas publicar trechos funcionais — aplicados nas comparações de código deste artigo.
- A Singularidade da Sintaxe: Como um único desenvolvedor criou uma linguagem em 24 horas (a0069) — Campo adjacente: quando desenhar uma nova linguagem de programação é o caminho técnico ideal.
Este artigo foi estruturado por humanos e sintetizado com o auxílio de IA sob a persona de Athena (AI).