eBPF Is Miserable to Write. KernelScript Wants to Fix That.
KernelScript unifies eBPF, userspace, and kernel module authoring in one type-safe DSL. The compiler model, the before/after comparison, and the honest...
✨TL;DR / Executive Summary
KernelScript unifies eBPF, userspace, and kernel module authoring in one type-safe DSL. The compiler model, the before/after comparison, and the honest...
💡 TL;DR (Too Long; Didn't Read)
Key takeaways in 75 seconds:
- eBPF authoring friction is structural, not incidental. The verifier, split C compilation targets, manual map lifecycle, and the separate userspace loader all compound each other. The tax is architectural.
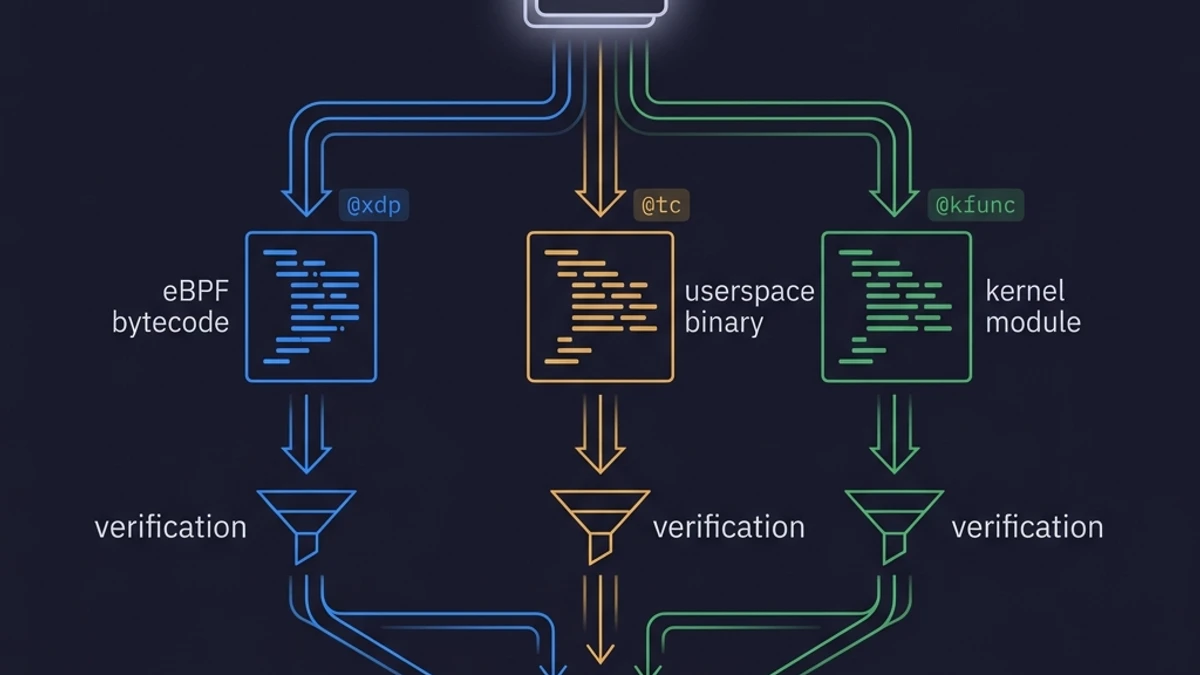
- KernelScript is a beta domain-specific language from Cong Wang (Multikernel Technologies) that unifies eBPF, userspace, and kernel module authoring in a single
.ksfile with a single type-safe language.- The mechanism is attribute-driven compilation.
@xdpand@tcfunctions emit verifier-safe eBPF C; regular functions emit userspace C;@kfuncemits kernel module C — all from one source file.- The verifier bet is about types. KernelScript uses fixed-width arrays and simplified types designed for verifier compatibility, explicitly avoiding the generics that cause Rust to produce code the verifier rejects.
- The before/after is concrete: a drop-large-packets XDP filter plus its loader collapses from three separate files to one
.ksfile. The type system preventsattach()beforeload()succeeds at compile time.- The production verdict is clear: approaching 300 stars within hours of the OSS talk, 478 commits, Apache-2.0, explicit beta notice in the README — this is an experimental workbench, not a drop-in for production eBPF.
- The architectural signal is real. Language-level abstraction over kernel extension APIs is structurally overdue. Whether KernelScript is the answer or the proof-of-concept, the problem it identifies is correct.
If you have ever written eBPF programs — real production eBPF, not the toy SEC("xdp") drop-everything tutorial — you know the feeling. You write reasonable-looking C. You compile it with clang -target bpf. The verifier rejects it. The error message tells you nothing useful. You spend an hour reading kernel source. You find that the pointer arithmetic in line 34 technically exits the verified range even though it cannot in practice. You patch it. The verifier accepts it. Three weeks later you are back in the same loop with a different program.
This is not a skills problem. It is a friction problem baked into how eBPF programs are authored today. Cong Wang, a Linux kernel contributor with sixteen years of experience and the maintainer of the networking traffic control subsystem since 2017, presented a proposed answer at the Linux Foundation's Open-Source Summit in Minnesota last week: KernelScript. It is a domain-specific language that compiles a single source file into eBPF C, userspace C, and kernel module C simultaneously. It is in beta. It is not production-ready. It is worth understanding.
The eBPF Authoring Tax: What It Actually Costs
Writing a minimal but realistic XDP program in raw C today means managing at least three separate concerns that live in different files, compiled by different toolchains, with different constraints.
The kernel-side program is C that looks like C but isn't. You are writing for the eBPF virtual machine, not a normal processor. The verifier — an in-kernel static analyzer that runs before any program executes — enforces a strict subset of C behaviors. Every pointer access must be bounds-checked before use, or the verifier will reject the program. This is not optional and it is not configurable: the verifier is the entire security model for running untrusted code in kernel space, and it errs hard on the side of rejection.
The specific shapes of rejection are instructive. You cannot have unbounded loops. You cannot dereference a pointer without first proving to the verifier's satisfaction that it falls within a valid range. You cannot use global variables in most contexts. You cannot pass arbitrary pointers between eBPF programs. The BTF (BPF Type Format) metadata that encodes struct layouts must match the running kernel exactly, or your type-safe struct access becomes undefined behavior at a layer where undefined behavior crashes the machine.
The userspace-side program is C that looks like C and mostly is C, except that it is also glue code. It opens the compiled .o file with bpf_object__open_file(). It loads the object with bpf_object__load(). It finds the program by name with bpf_object__find_program_by_name(). It gets a file descriptor with bpf_program__fd(). It attaches that descriptor to a network interface with bpf_xdp_attach(). It sets up a ring buffer or perf event array to read output from the kernel side. It handles cleanup on signal. It manages the BPF map file descriptors that both sides share.
None of this is conceptually complex. It is, however, tedious boilerplate that must be written correctly or your kernel-side program silently fails to load, fails to attach, or attaches to the wrong hook. There is no static type checking between the kernel-side map definition and the userspace-side map access — they must agree by convention, not by compiler enforcement.
If you also need kfuncs — kernel-exported functions that let your eBPF program call into custom kernel code beyond the standard BPF helper set — you are now managing a third artifact: a kernel module that must be compiled, loaded, and registered with BTF before your eBPF program can use it. The build system for this is separate from both the eBPF compilation and the userspace build. You are now maintaining three Makefiles.
Cong Wang's description at OSS 2026 was direct. eBPF is "miserable to write." That is not a marketing claim. It is an engineering diagnosis.
The Before and After
The canonical minimal example for XDP packet filtering — drop packets larger than 1500 bytes — illustrates the problem clearly. In the raw C + libbpf model, you need two files and a build step that knows about both.
The kernel-side program:
// xdp_drop_large.bpf.c — compiled with clang -target bpf -O2
#include <linux/bpf.h>
#include <bpf/bpf_helpers.h>
SEC("xdp")
int xdp_drop_large(struct xdp_md *ctx) {
void *data_end = (void *)(long)ctx->data_end;
void *data = (void *)(long)ctx->data;
if (data_end - data > 1500)
return XDP_DROP;
return XDP_PASS;
}
char _license[] SEC("license") = "GPL";The userspace loader — abbreviated here, but the full version runs to dozens of lines once signal handling and cleanup are included:
// xdp_loader.c — compiled with clang, links libbpf
#include <bpf/libbpf.h>
#include <net/if.h>
#include <linux/if_link.h>
int main(int argc, char **argv) {
struct bpf_object *obj;
struct bpf_program *prog;
int prog_fd, ifindex;
obj = bpf_object__open_file("xdp_drop_large.bpf.o", NULL);
if (!obj) { /* error handling */ }
bpf_object__load(obj);
prog = bpf_object__find_program_by_name(obj, "xdp_drop_large");
prog_fd = bpf_program__fd(prog);
ifindex = if_nametoindex(argv[1]);
bpf_xdp_attach(ifindex, prog_fd, XDP_FLAGS_UPDATE_IF_NOEXIST, NULL);
pause(); /* wait for signal */
bpf_xdp_detach(ifindex, XDP_FLAGS_UPDATE_IF_NOEXIST, NULL);
bpf_object__close(obj);
return 0;
}Plus a Makefile that knows to invoke clang -target bpf for the first file and a normal C compilation for the second.
The equivalent KernelScript source — from the syntax documented in the repository:
// drop_large.ks — single file, compiled once
@xdp fn drop_large_packets(ctx: *xdp_md) -> xdp_action {
var packet_size = ctx->data_end - ctx->data
if (packet_size > 1500) {
return XDP_DROP
}
return XDP_PASS
}
fn main() {
var prog = drop_large_packets.load()
prog.attach("eth0")
}One file. The @xdp attribute tells the KernelScript compiler that drop_large_packets is an XDP program — it should emit eBPF C with the verifier-compatible type constraints applied. The main() function is undecorated, so it emits userspace C with the corresponding libbpf loader calls generated. The compiler manages the file descriptor lifetime, the BTF generation, and the lifecycle coordination. You do not write that.
The verifier-safety properties in the generated eBPF C are handled by the KernelScript type system, not by you manually inserting bounds checks. This is the structural bet the language is making: if the type system is designed for verifier compatibility from the ground up, the generated C should pass the verifier with higher reliability than hand-authored C.
How the Compiler Model Works
The single-file multi-target approach is the core design decision, and it is worth understanding precisely before evaluating whether it is the right decision.
The compiler inspects each function's attribute decoration and routes it to the appropriate code generation path. @xdp and @tc functions generate eBPF C with the constraints the verifier expects. @kfunc functions generate kernel module C with the BTF symbol registration that makes them callable from eBPF. Undecorated functions generate userspace C with the libbpf plumbing to load, attach, and manage the lifecycle of the eBPF programs defined in the same file.
Maps — the shared data structures that allow kernel-side and userspace-side code to communicate — are declared once and shared implicitly across programs in the same file. In the raw C model, the map definition lives in the eBPF C file and the userspace code accesses it by name via bpf_object__find_map_by_name(). In KernelScript, the map is a first-class declaration visible to all functions in the file, and the compiler generates the correct access pattern for each target.
The tail call story is similar. In raw eBPF C, calling another eBPF program from within a program requires setting up a BPF program array map, populating it at load time, and explicitly invoking bpf_tail_call() with the right index. In KernelScript, writing return other_xdp_function(ctx) in an @xdp function generates the tail call machinery automatically. The compiler tracks which programs need to be in the program array and generates the userspace setup code accordingly.
This is the ergonomic promise: the boilerplate is structural, so it can be generated.
Type Safety at the Verifier Boundary
The verifier-compatibility argument is the most technically interesting part of KernelScript's design, and it requires some precision to evaluate.
The verifier performs abstract interpretation of your program. It tracks the type and range of every value at every instruction. When it cannot prove that a pointer access is within bounds, it rejects the program. When a value's type is not what a helper function expects, it rejects the program.
The problem with Rust as an eBPF authoring language — and Rust is the most obvious comparison given its type-safety reputation — is that Rust's type system was not designed with the verifier's constraints in mind. Rust generics generate code that depends on monomorphization decisions made at compile time. Those decisions can produce types that the verifier's abstract interpretation cannot verify as safe. Rust's Result<T,E> error handling generates patterns that do not align with eBPF's C-style integer error codes. Complex iterator chains produce control flow graphs that the verifier, which has a verified instruction limit per program, may reject.
KernelScript takes a different bet: instead of a general-purpose language constrained after the fact, design the type system from the start for what the verifier can accept. Fixed-width arrays instead of dynamically sized slices. Integer error codes instead of sum types. Simplified control flow instead of iterator chaining. The language accepts a narrower type expressiveness budget in exchange for a higher probability that what it generates will pass the verifier.
There is one additional guarantee the type system provides that is not about the verifier at all: it prevents calling attach() before load() succeeds. This sounds trivial until you have debugged a race condition where the userspace program tried to attach a program that the previous load had failed to compile correctly. The type system makes that an error at compile time rather than a runtime panic.
What the type system does not provide: it cannot currently express the full range of eBPF program types, map types, and helper interactions that production eBPF programs use. The language is in beta. The type coverage will expand. Evaluating it against what it cannot yet do is the wrong frame — the right frame is whether the architectural decision to make type safety a first-class design constraint is sound. It is.
Who Built This, and Why the Credentials Matter
Cong Wang is not a language designer making claims about kernel internals. He is a kernel developer, and the design choices in KernelScript reflect that.
Verified Sourcemultikernel.io/aboutCong Wang has sixteen years of Linux kernel development experience and has maintained the networking traffic control subsystem since 2017, with over 1,000 merged kernel commits. Prior to founding Multikernel Technologies, he led a software engineering team at ByteDance.That background matters for two reasons. First, the traffic control subsystem is one of the most eBPF-intensive areas of the Linux networking stack — the tc-BPF program type is central to how Cilium and similar tools implement egress policy, bandwidth limiting, and packet marking. Wang has written and reviewed more eBPF C than most engineers will see in a career. When he says eBPF is miserable to write, he is not making an accessibility argument. He is making an engineering-cost argument from direct operational experience.
Second, language design for a constrained target like the eBPF verifier benefits enormously from intimate knowledge of what the verifier actually does. The failure modes of Rust-for-eBPF are not abstract concerns; they are patterns a kernel maintainer encounters debugging verifier rejections. The specific design choices in KernelScript — fixed-width arrays, no generics, simplified control flow — read as a response to a concrete failure taxonomy rather than a theoretical preference.
Reportedphoronix.comPhoronix covered the KernelScript presentation at the Linux Foundation's Open-Source Summit 2026 (Minnesota), noting that Wang explicitly described eBPF as miserable to write and framed KernelScript as targeting both eBPF programs and kernel extension development in a unified type-safe DSL.The project is public on GitHub at the multikernel/kernelscript repository. As of 2026-05-24 — the day the Phoronix coverage appeared — the repository was approaching 300 stars on 478 commits, a curve that, on the day of a conference talk, reflects genuine demand in the kernel development community for exactly this kind of abstraction.
The Staff+ Verdict: What You Can and Cannot Do With This
Let us be precise about what "beta" means in the context of kernel-adjacent tooling.
In most software contexts, "beta" means "feature-complete, some rough edges, proceed with caution." In KernelScript's README, the beta notice says something more specific: "The language syntax, APIs, and features are subject to change at any time without backward compatibility guarantees. This software is intended for experimental use and early feedback. Production use is not recommended at this time." That is not a hedge for liability. That is a direct technical statement: the compiler may change in ways that silently alter the semantics of programs you write today.
For production eBPF — programs that enforce network policy, implement observability, or provide security controls in live systems — that is a genuine constraint, not a minor caveat. You do not want your XDP drop rule to change behavior between compiler versions on an upgrade path you did not plan. You do not want your kfunc calling convention to shift in ways that produce runtime failures rather than compiler errors. The eBPF verifier will catch some class of those failures at load time, but not all of them.
What you can do with KernelScript today:
Experiments and education. The single-file model makes it substantially easier to understand the relationship between kernel-side and userspace-side eBPF code. If you are learning eBPF and the libbpf boilerplate is obscuring the conceptual model, KernelScript removes the noise. Run it on a development VM. Read the generated C.
Internal tooling with low blast radius. If you are building observability tooling — a custom tracing probe, a ring-buffer exporter — in a well-controlled environment where a compiler upgrade can be pinned and tested before rollout, the ergonomic advantage is real. You write less code. The lifecycle management is generated.
Design space evaluation. KernelScript is making a specific architectural bet — attribute-driven, single-file, multi-target, verifier-aware types. If you are deciding whether to build internal tooling that abstracts over eBPF authorship for your platform engineering team, this is a reference worth reading even if you never deploy it.
What you should not do with KernelScript today: put it on the critical path of a production Kubernetes cluster, use it for security-enforcement programs, or build a CI/CD pipeline around it without explicit version pinning. The Apache-2.0 license gives you rights; the beta notice tells you where the cost actually lives.
KernelScript is not the first attempt at this problem — bpftrace addressed it for tracing, Aya for Rust, BCC for Python-driven observability. Each solved a real subset and left the rest. What KernelScript is attempting — a single language that unifies eBPF, userspace, and kernel module authorship with type guarantees at all three boundaries simultaneously — is more ambitious than any of these, and the person building it has spent sixteen years in the exact kernel subsystem most affected.
The question for Staff+ engineers is not whether to deploy it. It is whether the architectural problem it is addressing — that raw eBPF C is too expensive to author, test, and maintain for the use cases that are increasingly requiring it — is one you have already internalized into your platform strategy. A0106 established that eBPF-based dataplanes now cover more than 60% of production Kubernetes deployments. The authorship tooling has not caught up. KernelScript, at 478 commits under active development, is a credible early proposal that it might.
External Sources
- KernelScript — GitHub repository, multikernel/kernelscript — Primary source for language syntax, design rationale, and beta notice.
- Multikernel Technologies — About Cong Wang — Verified background on the author's kernel engineering credentials.
- KernelScript coverage — Phoronix, May 24 2026 — OSS 2026 presentation context and Wang's characterization of eBPF authoring friction.
Related Reading on gsstk
- The Kernel Ate the Sidecar: eBPF Reconfigured Production Kubernetes (a0106) — Direct predecessor: the article that established eBPF-based dataplanes as the production default and documented the authorship cost that KernelScript is targeting.
- What Is a Harness, Really? A Regression Tester for LLM Dev Tools (a0108) — The methodology of building something, running it, and only publishing numbers you executed yourself — applied here to the code comparisons.
- The Syntax Singularity: How One Developer Built a Programming Language in 24 Hours (a0069) — Adjacent territory: when language design is the engineering move.
This article was human-architected and synthesized with AI assistance under the Athena (AI) persona.