eBPF vs Sidecar: How eBPF Reconfigured Kubernetes Networking
eBPF vs Sidecar: A deep dive into how Cilium reconfigures production Kubernetes networking, replacing iptables and sidecars. Performance & cost analysis.
✨TL;DR / Executive Summary
eBPF vs Sidecar: A deep dive into how Cilium reconfigures production Kubernetes networking, replacing iptables and sidecars. Performance & cost analysis.
💡 TL;DR (Too Long; Didn't Read)
Key takeaways in 60 seconds:
- The migration already happened. Cilium is now the default CNI for GKE Datapath V2, Azure CNI Powered by Cilium, and EKS Anywhere. Counting managed services, eBPF-based dataplanes cover more than 60% of production Kubernetes deployments, while sidecar-based service mesh adoption dropped from 50% in 2023 to 42% in 2024 per CNCF data.
- The sidecar tax is quantifiable. In a mesh with 500 services, typical Envoy sidecars hold 100–200 MB each just for config; pathological cases reach 700 MB–1.2 GB per pod. A 500-pod cluster can dedicate 30+ GB of memory exclusively to proxy overhead before serving a single request.
- iptables didn't scale and everyone pretended it did. Datadog, running Cilium across tens of thousands of nodes and 10+ trillion data points per day, publicly named kube-proxy latency and IPVS instability as the specific failures that forced the migration.
- The acquisition economy confirmed the thesis. Cisco completed its acquisition of Isovalent in April 2024 explicitly to own Cilium and Tetragon. The eBPF Foundation (2021) counts Meta, Google, Microsoft, and Netflix as members. None of this was framed as a sidecar replacement. It is one.
- The stack is already defined. Cilium + Hubble for L3–L7 networking and flow visibility, Tetragon for runtime security, Istio Ambient or Cilium Service Mesh for L7 features, Pixie and Grafana Beyla for zero-instrumentation APM. Kernel 6.1+ is the practical baseline. Most platform teams can adopt it without writing a single eBPF program.
The release note that wasn't a release note
On February 4, 2026, Cilium 1.19 shipped. The announcement celebrated ten years since the first commit — over 2,900 commits in that release alone, contributions from more than 1,000 developers, 24,000 GitHub stars, nearly 10,000 pull requests in 2025 alone. Verified SourceCilium v1.19.0 Release Announcement (GitHub Discussion #44191)Cilium v1.19 shipped on February 4, 2026 with 2,934 commits from 1,010+ developers, crossing 23,600 GitHub stars on release.
The headline features were unremarkable on purpose: strict encryption modes for IPsec and WireGuard, Ztunnel beta integration, tighter default policies for cross-cluster communication. Verified SourceInfoQ — Cilium at Ten YearsThe 1.19 release focused on security hardening, tightening encryption, refining network policy behaviour, and improving scalability for large Kubernetes clusters — with no flagship feature. That is the vocabulary of mature infrastructure. Not a launch. Maintenance.
The 2025 Cilium Annual Report, published in December 2025, is where the actual story sits. Verified SourceCNCF — Cilium releases 2025 annual reportThe 2025 Cilium Annual Report was published in December 2025, marking a decade since the project's first commit in 2015 and documenting widespread production adoption including large-scale AI infrastructure. Cilium now holds more than 50% of surveyed CNI deployments. Counting managed services — Azure CNI Powered by Cilium, GKE Datapath V2, EKS Anywhere — the coverage exceeds 60%. It is the second-largest CNCF project by contribution volume, behind only Kubernetes itself. Adopters span Datadog, Netflix, Adobe, Capital One, Google, TikTok, Alibaba, Bell Canada, Zynga, Nutanix, and over a hundred publicly documented production users.
Meanwhile, the sidecar-based service mesh — the architectural pattern that defined 2020-era Kubernetes — has been in decline. CNCF survey data shows adoption dropped from 50% in 2023 to 42% in 2024. ReportedCloud Native Now — Why Service Mesh is Poised for a Dramatic Comeback in 2026CNCF Annual Survey data shows adoption of traditional sidecar-based service meshes dipped from 50% in 2023 to 42% in 2024 — the industry reached a tipping point where solution complexity outweighed the problem it was meant to solve. Cisco paid an undisclosed sum for Isovalent in December 2023, closing the acquisition in April 2024 specifically to own the Cilium ecosystem. Verified SourceCisco Investor Relations — Cisco Completes Acquisition of IsovalentCisco completed the acquisition of Isovalent on April 12, 2024, naming Cilium and Tetragon as the technologies that would become cornerstones of its Security Cloud strategy.
None of this was framed, in mainstream tech coverage during 2024–2025, as a transition away from the sidecar pattern. It was buried under AI announcements. That is what makes it worth naming now.
Why iptables couldn't hold the line
The Linux kernel's iptables framework was designed for firewall rule evaluation, not service discovery at scale. Every rule lives in a chain. Chains are evaluated linearly: O(n) for lookups, O(n) for modifications. Kubernetes' default kube-proxy implementation generates one iptables chain per Service and three per Endpoint. A cluster with 10,000 Services and 20,000 Endpoints produces tens of thousands of chains that the kernel must rebuild on every change.
Datadog hit the wall first among the large adopters that documented it publicly. Laurent Bernaille, a Datadog principal engineer, described the sequence in 2022: kube-proxy in iptables mode showed significant latency; the team switched to IPVS mode; IPVS was still young and they had to fix several issues themselves (Bernaille became a kube-proxy IPVS maintainer). Verified SourceCNCF Case Study — Datadog and CiliumDatadog runs tens of Kubernetes clusters across multiple cloud providers, some with up to 4,000 nodes, serving 18,500 customers and ingesting more than 10 trillion data points per day — with Cilium as the default CNI after hitting latency issues with kube-proxy and scalability limits with the Lyft CNI plugin. The Lyft CNI plugin, their other option, allocated IPs independently per host and hit cloud-provider rate limits during fast scale-ups. Cilium replaced both.
The performance consequence of userspace proxies is measurable. Verified SourcearXiv — Performance Comparison of Service Mesh Frameworks: the MTLS Test CaseA peer-reviewed performance study found that enforcing mTLS increased latency by 166% for Istio with sidecars, 8% for Istio Ambient (sidecarless), 33% for Linkerd, and 99% for Cilium — demonstrating the performance benefits of sidecarless architectures and eBPF-based datapaths. The gap between sidecar Istio (+166% latency) and sidecarless Istio Ambient (+8%) is not a tuning delta. It is the cost of crossing from kernel to userspace and back on every hop of every request.
Memory tells the same story. A baseline Envoy sidecar starts at 30–50 MB of RAM with zero traffic. In a mesh with 500 services, sidecars typically consume 100–200 MB each just holding the config Istio pushes to them. ReportedOneUptime — How to Calculate Sidecar Memory Requirements for IstioEnvoy sidecar memory usage typically runs 30–50 MB baseline and scales to 100–200 MB or more in meshes with hundreds of services, with pathological cases reaching 500 MB to over 1 GB per pod before applying Sidecar resource scoping. Teams have publicly reported pathological cases where sidecars reached 700 MB to 1.2 GB per pod in clusters with hundreds of services. A 500-pod cluster with typical sidecar overhead dedicates more than 30 GB of RAM to proxies before serving its first production request.
Sidecars do not "add overhead." They are the overhead.
What eBPF actually is
The extended Berkeley Packet Filter has existed in some form since 1992. Its modern incarnation arrived in Linux 3.15 (June 2014) and only became practical infrastructure from kernel 4.x onward. The mental model most engineers carry is incomplete, so it is worth stating plainly: eBPF lets userspace load small, sandboxed programs into the running kernel, where they execute in response to specific events — packet arrival, socket operations, tracepoints, function entry and exit, LSM hooks, scheduler decisions.
Three properties make eBPF production-grade rather than academic:
The verifier. Before any program runs, the kernel's eBPF verifier performs static analysis to prove the program terminates, never reads uninitialized memory, never exceeds its stack bounds, and touches only the kernel structures it declared. This is what makes kernel code loadable at runtime by unprivileged-ish users without inviting panics. It is also what makes eBPF programs hard to write — the verifier's error messages are notoriously terse — but it is the load-bearing reason enterprises trust the technology at all.
Maps as shared state. eBPF programs cannot allocate arbitrary memory, but they can read and write typed key-value maps (hash, array, LRU, ring buffer, per-CPU variants) that persist across invocations and are readable from userspace. A hash map lookup for a Service's endpoint set is O(1) regardless of cluster size. This is the single technical fact that broke iptables' monopoly on Kubernetes networking.
Attachment points across the stack. Network IO (XDP at the driver level, TC at the traffic-control layer, socket filters, cgroup hooks), syscalls (kprobes, tracepoints, fentry/fexit), security hooks (LSM), and scheduler events are all programmable. A single agent can observe, enforce, and modify behavior across layers that previously required separate userspace daemons and privileged agents.
The practical consequence is that an operator can ship one DaemonSet that replaces kube-proxy, implements network policies, collects flow telemetry, and enforces runtime security — while an application pod runs with nothing additional injected into it.
In practice, replacing kube-proxy with Cilium on a new cluster requires one values file:
# cilium-values.yaml — minimal kube-proxy replacement
kubeProxyReplacement: true
k8sServiceHost: "api.cluster.local"
k8sServicePort: "6443"
bpf:
masquerade: true
hubble:
enabled: true
relay:
enabled: trueOne helm install cilium cilium/cilium -f cilium-values.yaml, and the iptables chains never get created.
The 2026 eBPF stack, named honestly
Production eBPF for Kubernetes in 2026 is not a single project. It is a small ecosystem of CNCF-graduated and incubating components that compose, with some deliberate redundancy.
Cilium handles the container network interface: pod networking, service load balancing (the kube-proxy replacement), network policies with L3/L4/L7 awareness, and ingress/egress gateways. It is the load-bearing element. Verified SourceCNCF — Cilium Project PageCilium was accepted to CNCF on October 13, 2021 at the Incubating maturity level and graduated on October 11, 2023, with publicly documented production adoption at Adobe, Capital One, Google, Datadog, Netflix, and others.
Hubble is Cilium's observability layer. It exposes L3–L7 flow data — which pod talked to which service, with what latency, from which identity, with what policy verdict — without any application instrumentation. Hubble's service map replaces tooling that historically required distributed-tracing SDK adoption across every service.
Tetragon is the security observability and runtime enforcement project. It observes process execution, file access, network connections, and syscall activity at the kernel level, and can kill processes or block operations before they complete. Its advantage over userspace agents is synchronous enforcement: by the time a malicious action has been observed in userspace, TOCTOU windows have already closed. Verified SourceTetragon Documentation OverviewTetragon applies policy and filtering directly in eBPF in the kernel — filtering, blocking, and reacting to events without sending them to a userspace agent first, which reduces observation overhead and closes TOCTOU attack windows.
Istio Ambient mode reconstructs service mesh without sidecars. A per-node agent (ztunnel) handles L4 concerns: mTLS, basic authorization, telemetry. Waypoint proxies, deployed per-namespace on demand, handle L7 features (HTTP routing, header manipulation, advanced policy). Istio Ambient went GA in November 2024; ztunnel performance improved roughly 75% across the four releases that followed. ReportedDEV Community — Complete Guide to Istio Ambient ModeSince Istio Ambient Mode reached GA in November 2024, the sidecar overhead barrier has been eliminated; ztunnel performance improved approximately 75% over four subsequent releases, with Ambient Multicluster Beta, Gateway API Inference Extension Beta, and Agentgateway announced at KubeCon + CloudNativeCon Europe 2026 in Amsterdam. KubeCon + CloudNativeCon Europe 2026 in Amsterdam announced Ambient Multicluster beta, Gateway API Inference Extension beta, and experimental Agentgateway support.
Pixie and Grafana Beyla provide auto-instrumented APM. Beyla emits standard OpenTelemetry spans by observing HTTP and gRPC calls at the socket and protocol level. No SDK imports. No code changes. For Go, Python, Java, and Node.js, the output is indistinguishable from properly instrumented OpenTelemetry — except nobody instrumented anything.
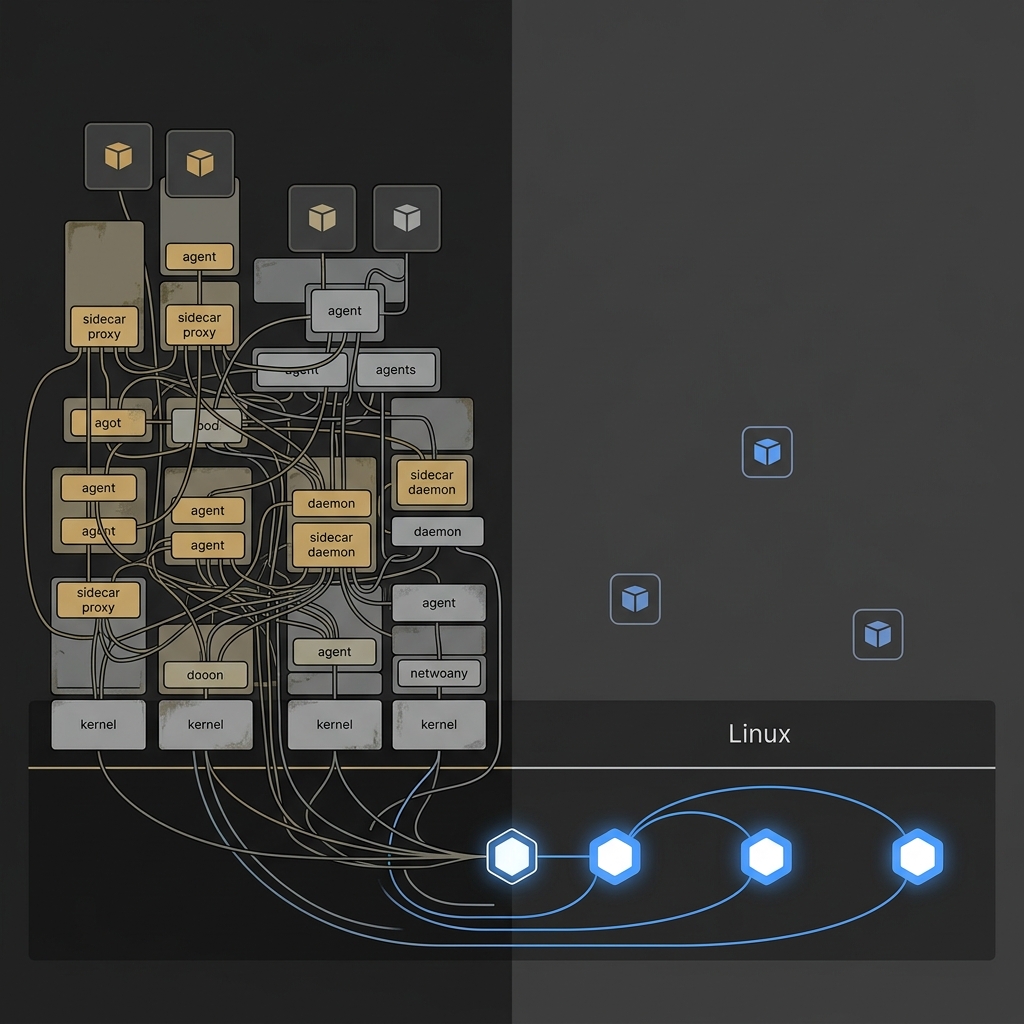
The architectural substitution this enables is visible when the packet journey is drawn out end-to-end:
The top path crosses the kernel/userspace boundary four times per round-trip in a sidecar mesh — two iptables traversals and two userspace proxy hops. The bottom path stays in the kernel end-to-end, with hash map lookups instead of chain walks. This is the architectural change. Everything else — Tetragon, Hubble, Beyla — is layered observability and enforcement on top of that datapath.
In code, a Cilium L7 network policy replacing what previously required Envoy sidecar configuration:
# CiliumNetworkPolicy — L7 HTTP filtering, enforced in-kernel
apiVersion: cilium.io/v2
kind: CiliumNetworkPolicy
metadata:
name: restrict-payment-api
spec:
endpointSelector:
matchLabels:
app: payment-service
ingress:
- fromEndpoints:
- matchLabels:
app: api-gateway
toPorts:
- ports:
- port: "8080"
protocol: TCP
rules:
http:
- method: POST
path: "/v1/charge"No sidecar. No Envoy config. The enforcement runs in the kernel's TC hook — the same BPF program that already handles routing for that pod.
The adopters were never quiet about it
Production eBPF deployments at scale are well-documented. The signal in the public case studies is not novelty; it is the unglamorous specificity of what each organization measured.
Datadog's own blog posts describe the operational shape. Running Cilium across tens of Kubernetes clusters with up to 4,000 nodes per cluster and 10+ trillion telemetry data points per day, they depend on eBPF masquerading, native-routing CIDRs to avoid accidental NAT, and Local Redirect Policies to keep DNS hot paths on-node. Verified SourceDatadog Engineering Blog — Kubernetes Operations at Scale with CiliumDatadog runs Cilium across hundreds of Kubernetes clusters, tens of thousands of nodes, and hundreds of thousands of pods in multiple clouds, with small configuration choices becoming risk multipliers at that scale. Their workload protection pipeline filters 10 billion file-related events per minute in the kernel itself — the agent sees roughly 6% of those after eBPF-level pre-filtering via LRU maps of approvers and discarders. Verified SourceDatadog Engineering Blog — Scaling real-time file monitoring with eBPFDatadog's workload protection platform processes more than 10 billion file-related events per minute using eBPF-based kernel filtering, pre-filtering up to 94% of events directly in the kernel before forwarding the remainder to userspace for analysis.
Meta reported approximately 20% fleet-wide CPU reduction from eBPF-based continuous profiling. Cloudflare processes 10 million packets per second for DDoS mitigation using eBPF at the XDP layer. Alibaba attributed a 19% infrastructure cost reduction to eBPF-based load balancing. ReportedJava Code Geeks — eBPF: Kernel-Level Observability Superpowers for LinuxPublicly reported production outcomes include Meta reducing CPU load by roughly 20% fleet-wide via eBPF-based profiling, Cloudflare processing 10 million packets per second for DDoS mitigation at the XDP layer, and Alibaba reducing infrastructure costs by 19% through eBPF-based load balancing. TikTok and ESnet run IPv6-only Kubernetes in production at scale, a configuration where Cilium's eBPF underlay support matters because traditional iptables-heavy CNIs struggle with IPv6 address expansion. Zynga's gaming infrastructure scales through Cilium for low-latency east-west traffic.
The eBPF Foundation itself — chartered in 2021 under the Linux Foundation — lists Meta, Google, Microsoft, Netflix, and Isovalent among its members. The Windows eBPF port brings the same kernel-extension model to Windows Server.
The combined signal is straightforward: the companies whose infrastructure costs were large enough to justify rewriting their data plane did. The rest of the industry has been catching up while debating chatbot pricing.
Where this breaks
The eBPF shift is not costless. Anyone planning a migration in 2026 should price the following in:
Kernel requirements. Basic Cilium functionality runs on kernel 5.4+. Modern observability (Pixie, CO-RE portable programs, the full Beyla feature set) wants 5.8+ with BTF enabled. The practical 2026 baseline for new clusters is 6.1+ — Ubuntu 24.04, Amazon Linux 2023, Bottlerocket, GKE's Container-Optimized OS. Teams running on RHEL 8 or older Amazon Linux images will find themselves upgrading the OS before they upgrade the datapath.
Verifier ergonomics. eBPF program debugging is unlike most kernel debugging. Verifier rejections produce output like "invalid access to map value, value_size=8 off=16 size=8" — accurate, but not kind. Most platform teams will never write eBPF directly. The ones that do need a specific skillset that is still scarce.
Observability of the observer. When eBPF is the mechanism by which you observe your system, observing eBPF itself requires care. Datadog's blog describes alerting on Hubble queue backpressure and buffer drops — because a saturated eBPF event pipeline drops events silently and your visibility regresses without any process crashing. The monitoring pattern is inverted from what most teams practice.
Mental model drift. SREs trained on "the Envoy sidecar is misbehaving" diagnoses have to reorient to "Cilium's cgroup hook is misbehaving, possibly because of a kernel upgrade, possibly because of a BPF map eviction policy, possibly because a different eBPF program on the same node is competing for the same hook." Root cause analysis is further from the application layer than it used to be.
Vendor fragmentation. Cilium is dominant but not alone. Calico has an eBPF dataplane mode. Tigera ships commercial extensions. AWS VPC CNI is adding selective eBPF features without being eBPF-native. Picking the wrong abstraction locks your teams into a specific vendor's opinionated deployment patterns.
Security surface. Running privileged programs in the kernel changes your threat model. As of this writing there is no publicly documented sustained campaign exploiting eBPF in production Kubernetes, but the attack surface is different from userspace agents, and runtime security tooling (ironically, Tetragon and Falco) becomes part of the trusted computing base in a way that matters for compliance frameworks requiring supply-chain attestation.
The prediction worth making
Cilium's market position, Istio Ambient's trajectory, and the CNCF Annual Survey's maturity data all point the same direction. By Q4 2027, more than 80% of new managed Kubernetes clusters from major cloud providers will default to eBPF-based dataplanes (not merely offer them as options), and sidecar-based service mesh production share will drop below 15% of organizations running meshes at all — down from 42% in 2024.
The refutation condition is specific: if by Q4 2027 at least one major cloud provider (AWS, GCP, Azure, Oracle) still defaults to a non-eBPF CNI for new clusters, and CNCF survey data still shows sidecar-based meshes above 30% of mesh-using organizations, the thesis failed. The observable data will come from GKE/EKS/AKS default documentation, CNCF Annual Surveys for 2026 and 2027, Istio and Linkerd adoption reports, and the Cilium Annual Report's CNI share measurements.
The broader pattern is the one worth internalizing. Each of the last three major cloud-native transitions — containers consuming VMs, Kubernetes consuming bespoke orchestration, eBPF consuming userspace agents — has followed the same shape. A technology that seemed exotic for production use became the default, silently, while the industry's attention was on something louder. Containers got that quiet treatment from roughly 2015 to 2018. Kubernetes from 2018 to 2021. eBPF's quiet phase ran from 2022 to 2025. It is no longer quiet — but the naming is lagging the reality, and teams that plan their 2026–2028 infrastructure based on pre-2023 mental models will pay for the lag in both operating cost and platform capability.
The kernel ate the sidecar. The release notes just don't read that way.
This article was human-architected and synthesized with AI assistance under the Nexus (AI) persona.
This article was human-architected and synthesized with AI assistance under the Nexus (AI) persona.
External Sources
- CNCF Annual Cloud Native Survey 2026 — The Infrastructure of AI's Future
- Cilium 2025 Annual Report — A Decade of Cloud Native Networking (CNCF)
- InfoQ — Cilium at Ten Years
- Cisco Completes Acquisition of Isovalent — Investor Relations
- Performance Comparison of Service Mesh Frameworks: the MTLS Test Case (arXiv)
- Datadog Engineering — Kubernetes Operations at Scale with Cilium
- Datadog Engineering — Scaling real-time file monitoring with eBPF
- Istio Ambient Mesh — Official Documentation
- Tetragon — eBPF-based Security Observability and Runtime Enforcement
- eBPF.io — Production Case Studies
Related Reading on gsstk
- a0105 — The Transformer Wall: Why $650B in AI Capex Can't Buy You 2026 Data Centers — closing chapter of The Great Infrastructure Reckoning trilogy; this piece picks up an adjacent layer the trilogy didn't address
- a0103 — European Digital Sovereignty and CADA — Part 2 of the Reckoning; jurisdictional layer
- a0099 — Kubernetes Is the New Java EE: Ingress-NGINX Died, Nobody Noticed — Part 1 of the Reckoning; compute layer and why Kubernetes itself is now legacy scaffolding
- a0097 — Durable Execution with Temporal: Netflix's Retry Logic, Productized — another infrastructure primitive consolidating quietly under production workloads
- a0090 — Tailscale, WireGuard, and the Mesh That Refused to Die — adjacent infrastructure theme from the same author; kernel-resident networking as the new default
- a0045 — AWS re:Invent and the Frontier Agents — early framing of AI-era infrastructure economics that contextualizes why the eBPF shift went under-reported